 |
| 図1 MPEG の動き検索モデル |
数日前 Windows 2000 の IPv6 Technology Preview で自ホストの v6 アドレスを知る方法は〜と騒いでいたけど、対処方法が判明した。
MSDN からではなく、Microsoft Research の IPv6 ページ からであれば IPv6 関連のツールの最新版ソースを入手することができて、その中に ipv6.exe のソースも含まれていたから、それを参考にすれば自ホストに割り当てられている IPv6 アドレスを列挙することが可能になる。
一応登録が必要だけど、誰でも入手できそうなので、IPv6 関連の作業の必要がある人は見てみると良いかも。
1周目は殺戮数が 250 にしか届かなかった為 A ランク止まり。現在芝村で2周目中なのだけど森精華が深入りして消されてしまったため多分 B ランク。殺戮数は 4/5 の時点で 170 匹。士翼号で切りまくってる。
速見が司令に転属して人が変わっているのでちとやな気分。コマンド目当てでほぼ全員(教師除く)と 120&120 状態であるため争奪戦が発生してもおかしくない状況なのだが、天才 level 3 なためやりたい放題。次回は何がなんでも密会技能をマスターしようと心に決める。
世界の謎? ん〜そんなんどーでもいいや。そのうち見えてくることでしょう。
再び IPv6 がらみ。どうやらローカルマシンの IPv6 アドレスを入手しようと思ったら DeviceIoControl で IPv6 のドライバに問い合わせをしなければいけないらしい。
クラクラするものを感じつつ、msipv6-1.4-src の EULA (ソース使ったソフト配布する場合は判別可能な機能追加がなきゃ駄目よ、研究とかの非営利目的じゃなきゃ変更を加えたソフト配布しちゃ駄目よ)を回避するため API の使い方を参考にするにとどめて実装。コンパイルを試みるも、devioctrl.h が開けないという無情な表示。
google をふらつき NT DDK を入手すればその中に devioctl.h はあるらしいと突き止め、延々 68M のダウンロード中。つーか、Windows2000SP1 で IPv6 対応の商用アプリケーションって作れるのかな〜。いくらなんでも MSDN から落とせる方の DLL を使うだけのものでもあんな EULA ということは無いはずなのだけど、この辺深く調べてないので不明。
しかしどうして 2000 SP2 用の IPv6 ドライバは無いのだろうね〜。IPv6 の実験環境に CodeRed パッチが当てられないじゃないか。
今更な話題だし、別に現在の総理と政策について何が言いたいわけでもないんです。ただそんな時代もあったんだなぁと。
同じことを考える方も多いようで、金解禁物語 なんてよくまとまってますね。
やっぱり SSE2 って駄目かも。
P4 で Lanczos3 を高速化すべく、SSE2 のコードでソース画像参照先アドレス決定時に PREFETCHT0 を呼ぶように修正してみたのだけど……呼ばない版と比べて比較用ソース&設定で 5 秒も遅くなってしまった。SSE2 で速くなった分をきっちり食いつぶして、MMX 版と同じ速度になってくれる。
多分何も考えずに、既にキャッシュに入っている場合でも PREFETCHT0 を呼んでるのが速度を悪化させてる原因だと思うけど、FETCH されるキャッシュサイズを考慮してループを展開するのは……やりたくないな〜。
やるとしたら、今は画素毎に呼んでる PREFETCHT0 を行をまたぐ毎に変更するとか、PREFETCHT0 を T1/T2/NTA を試してみるとかぐらいしか無さそう。
つか SSE2 の整数演算は使いにくくて仕方が無い。16bit の掛け算しかできないから精度を上げるのには向かないし。
TMPGEnc は Intel が最適化に協力するとかいう話だけど、本当に速くなるのかな。最適化しようとか考える場合って、なるべくメモリを読まずに済むように、読まなければ行けない場合はなるべくまとめてやるようにというのが基本で、SSE2 とかの SIMD 手法よりもそちらの方が効果的だと理解しているのだけど、それやると Athlon 系の方が最適化の恩恵を受けるんじゃないかな。MS-MPEG4 の場合のような手段を使わない限り。
私は 以前 確かに誓ったのです。既に覚えているものは誰もいないであろう誓いですが、それでも私は覚えています。私は誓いを破る訳にはいかないのです。
という訳で「歌月十夜」委託販売が開始されたので土曜日にさくっと入手。その日のうちにあらかた終わらせて「夢十夜」と投稿イラストはすべて埋まってる。ただし黄昏草月には CG 抜けがちらほら〜だけどここはスポイラーに頼る予定。
内容は……まだ入手できてないからやらないという人……いるのかな?
一応そういう方もいるかもしれないので一言感想のみ。せめて 8/15 か 8/16 ころにやりたかった。冬に遊ぶよりもましなんだろうけれども。というわけで入手済みでまだ遊んでないひとはとっととやっとくことをお勧めします。
DVD とか CSS とか改正著作権法についてあれこれ。以前 もちらっと触れたことがあるのだけど。というか、こんなところで書いてないで掲示板の方に直接書き込めばいいと思うのだけど、長文になりそうだから。
この問題の焦点は現行の平成12年11月29日改正著作権法での第30条にある。具体的にいうと、CSS のような「技術的保護手段」を回避して HDD 上にコピーする行為は「私的使用のための複製」とはみなされず、複製権の侵害とされるのだ。
この場合の罰則は第119条に規定されており、「3年以下の懲役」か「300万以下の罰金」ということになっている。と言うわけで、私は幇助罪に問われる危険性はおかしたくないので BBS でのその手の質問には答えない。
たとえ、自分で購入した DVD のチャプタ構成が腐っていて思うように再生できず、何とか好きなシーンだけを切り出して見たいと考えたのだとしても、CSS を解除して HDD にコピーし、GOP 単位編集ソフトでカット編集+再構成とかしようとしただけでも、それは違法行為となる。
が、PowerCapture Pro でのマクロビジョン解除の場合、あれはもともとマクロビジョンの検出機能が無いハードウェアを使用しているため第30条の「記録又は送信の方式の変換に伴う技術的な制約による除去又は改変を除く」に該当して「私的使用のための複製」の範囲に収まる。現行法を普通に読む場合その解釈しか出てこない。
ザル法であり、悪法であるとは思うけど、それでも法は法。法を変えようと努力しているので無く、この国に暮らすことで法から利益を受けているならば、法に従うべきだろう。
以上タテマエ以下ホンネ。
自分から犯罪行為してますとゲロってどうするんだボケ。オメーが捕まったらこっちの肩身まで狭くなるじゃないか、も少し考えやがれ。違法行為をすんならあんなオープンなところに出てくんな、もっと薄暗い地下を這いずり回ってろ。
CSS 解除する人全てを取り締まれない? あ〜 CCS キャプってエンコして CD-R に詰めて売ってて捕まった誰かさんもそゆこと考えてたんだろうね。あの逮捕があってから同じ犯罪の発生件数は減ったのだろうな〜。
昨日の戯言はちと毒を込めすぎたと反省しつつ、一つ誤りを発見したのでその修正と補足。
現行の平成12年11月29日改正著作権法での第30条
ここがミス、現行の著作権法は平成12年5月8日改正のもの、平成12年11月29日改正の著作権法が施行されるのは来月1日から。ただし、第30条の私的複製の例外事項は5月8日改正の現行著作権法にも入っている。
んで補足。CSS のような暗号化って「技術的保護手段」なの? という意見があるかもしれないけど、どう考えればそういう発想が出てくるのか私には理解できない。だって、著作権審議会マルチメディア小委員会ワーキング・グループ(技術的保護・管理関係)報告書 (平成10年12月10日) ってのがあるんだよ。この報告書の中の「技術的保護手段の実体」の中で、例として CSS が出てくるんだよ。
まーそれでも「CSS は技術的保護手段じゃない」と信仰するならもはや処置無しなのだけど。せめて捕まらないようにやってくれるのを祈るだけ。
やばい。上で書いたページもう少し読み進めてみたらなんか違うことが書いてある。恥の上塗りをしてしまったかも……。裏を取ってから後で書きます。
今回、著作権審議会マルチメディア小委員会ワーキング・グループ(技術的保護・管理関係)報告書 (平成10年12月10日) をテキストに使用します。一通り目を通しといてください。
まず第2章3節「技術的保護手段の実態」からの引用です。
CSS(Content Scramble System)
著作物等のデジタル信号を暗号化することにより,再生機器に組み込まれた機器による復号の操作を行わない限り,著作物等として鑑賞することができないようにするシステム。
DVDソフトでは,CGMSとCSSが組み込まれており,たとえCGMSの信号が無効化されても,CSSの復号が行われない限り鑑賞できないという技術を導入しており,これにより違法コピーされても復号する鍵がない場合は再生することができないので,違法複製物の使用防止の効果もあると考えられる。
と、このように CSS を技術的保護手段の実例として挙げています。しかし、続く第2章4節「回避に係る規制の対象とすべき技術的保護手段」では次のように著作権法で規制する技術的保護手段を明示的に、例を挙げて限定しています。
従って,現段階で対象となる具体的な技術的保護手段としては,上述した技術的保護手段の実態に照らせば,著作物等の利用のうち複製を制限する,SCMS,CGMS,擬似シンクパルス方式が該当することになると考えられる。
ここで、CSS は(一般的暗号化やソフトウェアのシリアルナンバーと同様に)回避の規制対象から外されています。少なくとも、立法時の意図としては CSS は(著作権法で回避が規制される)技術的保護手段ではないということです。
DVD の場合は CSS のみで保護されている訳ではなく、CGMS という仕組みも併用されています。著作権法で保護される技術的保護手段は DVD の場合 CGMS と、それを受けて生成されるアナログ信号での擬似シンクパルス(いわゆるマクロビジョン)に限定されるようです。
専用のハードウェア DVD プレイヤーの場合はこれで問題ないはずです。問題は DeCSS などの活躍の舞台である PC での DVD-ROM ドライブでの状況です。
CGMS+CSS で制限されている DVD ディスクの場合、通常ではディスク上のファイルをコピーしようとしても「デバイスは要求を処理できません」というエラーメッセージが表示される事と思います。おそらくこれが CGMS による保護なのでしょう。
ただし、ソフトウェア DVD プレイヤーを起動した後では、CGMS でコピー保護がかかっているはずの DVD プレイヤーからでも普通にファイルのコピーができてしまいます。特に autorun を有効にしている環境ではコピー不能のエラーメッセージを見ることの方が難しいと思います。
Windows OS とソフトウェア DVD プレイヤー、DVD-ROM ドライブという極めて普通の環境で可能なファイルコピーが違法行為であり、専用ソフトを用意しなければ不可能な CSS 解除が違法でないというのには何となく納得の行かないものを感じます。(それともファイルコピーができてしまうのは「記録又は送信の方式の変換に伴う技術的な制約による除去又は改変」なのでしょうか、それなら納得できるのですけど)
ただし、CSS の解除自体は違法でないとしても、DeCSS などのソフトには CGMS の保護を無効にする機能(ロックされている DVD ドライブからファイルを読み取る)が付属しているため、頒布目的での所持や公衆送信(可能状態に)することは著作権法第120条の2により「1年以下の懲役又は100万円以下の罰金」となるので止めておくことをお奨めします。
もしも CSS の解除のみを行い、CGMS の無効化を試みないソフトが存在した場合どうなるのかなという興味はありますが、私が知る限りその手のソフトは存在しないようなので CGMS で保護された DVD をコピーすることは違法であるという判断は間違ってはいないようです。
時報除去を 0.2.1 に更新しました。AUF から落せます。
1度フィルタを有効にしてから、フェードの設定値を変更してもフィルタに反映されないバグの修正です。もりのみやこ さん、報告ありがとうございました。
なんとなく BCC (Borland C++ Complier) での M4C の作り方を書いてみます。一部の方には役に立つかもしれないので。
一応 M4C の作者に連絡をとろうと試みたのですが、README に記載されている連絡先にメールを出しても返事が返ってこなかったため、非公認です。README に書かれている「配布条件」および「改変について」が本当ならば連絡をとらずとも問題は起きないはずなのですが。
まず Borland から入手した freecommandlinetools2.exe を実行します。するとインストール先(デフォルトでは C:\Borland\bcc55)をきいてくるので、好きな場所を選びましょう。(特に拘りがなければデフォルトのままが良いと思います)
次に、コンパイラなどへの PATH を通します。95 系の場合は AUTOEXEC.BAT に「SET PATH=%PATH%;インストール先フォルダ\bin」という行を追加しましょう。ここでインストール先フォルダという部分は実際にインストールしたフォルダへのパスに置き換えてください。デフォルトの設定でインストールした場合は C:\Borland\bcc55 です。
NT 系の場合はコントロールパネルから、システム -> 環境変数 と進み、PATH に「;インストール先フォルダ\bin」を追加してください。インストール先フォルダは、95 系と同様に実際にインストールしたフォルダへのパスを書かなければいけません。また、「;(セミコロン)」はここでは複数の要素を区切る場合に使われています。
最後に、bcc32.cfg ファイルと ilink32.cfg ファイル、2つのファイルを作成します。この2つのファイルを作成するフォルダは「インストール先フォルダ\bin」です。
bcc32.cfg には「-I"インストール先フォルダ\include"」という行と「-L"インストール先フォルダ\lib"」という2つの行を書き、ilink32.cfg には「-L"インストール先フォルダ\lib"」という行のみを書きます。
次に、各ファイルの例を示します。全て、デフォルトのインストール先フォルダに入れた場合の例です。
| C:\autoexec.bat |
loadhigh C:\WINDOWS\COMMAND\nlsfunc.exe C:\WINDOWS\country.sys SET PATH=%PATH%;C:\Borland\bcc55\bin REM 太字部分を追加 REM これ以外にも記述されている場合あり REM NT 系の場合は不要(コントロールパネルから設定) |
| C:\Borland\bcc55\bin\bcc32.cfg |
-I"C:\Borland\bcc55\include" -L"C:\Borland\bcc55\lib" |
| C:\Borland\bcc55\bin\ilink32.cfg |
-L"C:\Borland\bcc55\lib" |
これで Borland C++ Compiler のインストールは終了です。autoexec.bat に書きこんだ内容が有効になるように再起動したら、M4C のコンパイルができるか試してみましょう。
その前に、Makefile を書き換えなければいけないのを忘れていました。M4C の配布状態での Makefile は VC 用に書かれているので、これを BCC 用に変更します。次のように書き換えてください。
| 変更前 |
### for Borland C++ Compiler Setting #CC = bcc32 #CFLAG = -c -5 -K -O2 -Oc -OS -Ov #LFLAG = ### for Microsoft Visual C Setting CC = cl CFLAG = /c /G5 /O2 /Gr /J LFLAG = vfw32.lib advapi32.lib |
| 変更後 |
### for Borland C++ Compiler Setting CC = bcc32 CFLAG = -c -5 -K -O2 -Oc -OS -Ov LFLAG = ### for Microsoft Visual C Setting #CC = cl #CFLAG = /c /G5 /O2 /Gr /J #LFLAG = vfw32.lib advapi32.lib |
以上で準備は完了です。BCC のインストールが成功しているか試してみましょう。
MS-DOS プロンプト(95 系の場合、NT 系の場合はコマンドプロンプト)を起動し、「cd "M4C のソースフォルダ"」と打ち込みリターンキーを叩いてフォルダを移動してください。"M4C のソースフォルダ" を入力する場合は、フォルダを MS-DOS プロンプトウィンドウにドラッグ&ドロップすると楽ができます。
フォルダを移動したら、「make」と打ち込み、リターンキーを叩いて M4C のビルドを開始します。ここで「コマンドまたはファイル名が違います.」と表示された場合、PATH の設定に失敗しています。また、次のような長いエラーが表示される場合は bcc32.cfg の作成で失敗しています。
MAKE Version 5.2 Copyright (c) 1987, 2000 Borland bcc32 -c -5 -K -O2 -Oc -OS -Ov m4c.c Borland C++ 5.5.1 for Win32 Copyright (c) 1993, 2000 Borland m4c.c: エラー E2209 m4c.c 1: インクルードファイル 'stdio.h' をオープンできない エラー E2209 m4c.c 2: インクルードファイル 'stdlib.h' をオープンできない エラー E2209 m4c.c 3: インクルードファイル 'string.h' をオープンできない エラー E2209 m4c.c 4: インクルードファイル 'windows.h' をオープンできない エラー E2209 m4c.c 5: インクルードファイル 'winreg.h' をオープンできない エラー E2209 m4c.c 6: インクルードファイル 'vfw.h' をオープンできない エラー E2209 m4c.c 7: インクルードファイル 'limits.h' をオープンできない エラー E2209 m4c.c 8: インクルードファイル 'time.h' をオープンできない エラー E2209 m4c.c 9: インクルードファイル 'signal.h' をオープンできない エラー E2209 filename.h 1: インクルードファイル 'stdlib.h' をオープンできない エラー E2209 vfapi_read.h 11: インクルードファイル 'vfw.h' をオープンできない エラー E2139 vfapi.h 12: 宣言に ; がない エラー E2238 vfapi.h 13: 'DWORD' の宣言が複数見つかった エラー E2344 vfapi.h 12: 一つ前の 'DWORD' の定義位置 エラー E2139 vfapi.h 13: 宣言に ; がない エラー E2238 vfapi.h 14: 'DWORD' の宣言が複数見つかった エラー E2344 vfapi.h 12: 一つ前の 'DWORD' の定義位置 エラー E2139 vfapi.h 14: 宣言に ; がない エラー E2238 vfapi.h 15: 'DWORD' の宣言が複数見つかった エラー E2344 vfapi.h 12: 一つ前の 'DWORD' の定義位置 エラー E2139 vfapi.h 15: 宣言に ; がない エラー E2257 vfapi.h 21: , が必要 エラー E2084 vfapi.h 70: 関数本体でパラメータ名だけが使われている エラー E2147 vfapi.h 71: 引数宣言は 'VF_FileHandle' で始められない エラー E2084 vfapi.h 72: 関数本体でパラメータ名だけが使われている エラー E2228 vfapi.h 72: エラーあるいは警告が多すぎる *** 26 errors in Compile *** ** error 1 ** deleting m4c.obj |
BCC のインストールに成功している場合、次のようなエラーが表示されるはずです。
MAKE Version 5.2 Copyright (c) 1987, 2000 Borland bcc32 -c -5 -K -O2 -Oc -OS -Ov m4c.c Borland C++ 5.5.1 for Win32 Copyright (c) 1993, 2000 Borland m4c.c: エラー E2238 m4c.c 95: 'INPUT' の宣言が複数見つかった エラー E2344 C:\usr\local\borland\bcc55\include\winuser.h 4804: 一つ前の 'INPUT' の定義位置 警告 W8075 m4c.c 721: 問題のあるポインタの変換(関数 m4c ) 警告 W8075 m4c.c 731: 問題のあるポインタの変換(関数 m4c ) 警告 W8002 m4c.c 770: アセンブラを使うためコンパイルを再起動した(関数 m4c ) エラー E2238 m4c.c 95: 'INPUT' の宣言が複数見つかった エラー E2344 C:\usr\local\borland\bcc55\include\winuser.h 4804: 一つ前の 'INPUT' の定義位置 警告 W8075 m4c.c 721: 問題のあるポインタの変換(関数 m4c ) 警告 W8075 m4c.c 731: 問題のあるポインタの変換(関数 m4c ) 警告 W8057 m4c.c 854: パラメータ 'sig' は一度も使用されない(関数 sigint_handler ) *** 2 errors in Compile *** ** error 1 ** deleting m4c.obj |
これは、M4C のソースに問題があるためのエラーで、これが出れば BCC のインストールには成功しています。M4C のソースの修正については次回になります。
前回で BCC のインストールは完了しました。今回は前回の最後で出たエラーの修正です。まず警告は当面無視することにして、エラーから修正していくことにします。
エラーメッセージは4行出力されていますが、このうち重要なのは最初の「エラー E2238 m4c.c 95: 'INPUT' の宣言が複数見つかった」の行のみです。次の「エラー E2344 C:\usr\local\borland\bcc55\include\winuser.h 4804: 一つ前の 'INPUT' の定義位置」というのは最初のエラーの補足情報で、その4行下にあるエラーは最初のエラーと全く同じ繰り返しです。
このエラーの内容は winuser.h で既に宣言されている INPUT と言う構造体が、m4c.c の 95 行目で再定義されたというものです。これを解決するには m4c.c 側での INPUT を別の名前に変更するだけで済みます。
具体的には m4c.c の 95 行目で INPUT を VIDEO_INPUT と書き換え、688 行目の INPUT も VIDEO_INPUT と書き換えるだけです。それぞれ変更前・変更後の行は次の表のようになります。
| 95 行 | 688 行 | |
| 変更前 | }INPUT; | INPUT in; |
| 変更後 | }VIDEO_INPUT; | VIDEO_INPUT in; |
この二つを書き換えた後で make を実行すると、今度は次のエラーが表示されます。
MAKE Version 5.2 Copyright (c) 1987, 2000 Borland bcc32 -c -5 -K -O2 -Oc -OS -Ov m4c.c Borland C++ 5.5.1 for Win32 Copyright (c) 1993, 2000 Borland m4c.c: 警告 W8075 m4c.c 721: 問題のあるポインタの変換(関数 m4c ) 警告 W8075 m4c.c 731: 問題のあるポインタの変換(関数 m4c ) 警告 W8002 m4c.c 770: アセンブラを使うためコンパイルを再起動した(関数 m4c ) 警告 W8075 m4c.c 721: 問題のあるポインタの変換(関数 m4c ) 警告 W8075 m4c.c 731: 問題のあるポインタの変換(関数 m4c ) 警告 W8057 m4c.c 854: パラメータ 'sig' は一度も使用されない(関数 sigint_handler ) エラー E2133: コマンド 'tasm32.exe' を実行できない ** error 1 ** deleting m4c.obj |
最終行の「エラー E2133: コマンド 'tasm32.exe' を実行できない」の原因はインラインアセンブラです。m4c.c では 770 行で「__asm { finit };」というインラインアセンブラを使用しています。
無料版の BCC の場合、tasm32.exe(アセンブラ)が付属していない為インラインアセンブラの処理ができなくなっています。ので 770 行目をインラインアセンブラを必要としない形に書きかえなければなりません。
幸いここで使用されている finit は浮動小数点レジスタの初期化を行うだけの命令で、丁度同じ機能をもつライブラリ関数 _clearfp() が用意されているのでそれを使用します。まず 770 行の「__asm { finit };」をそのまま「_clearfp();」に書き換え、m4c.c の先頭に「#include <float.h>」を追加します。
以上の修正が完了してから make を実行すると、エラーで止まらずに m4c.exe が作成されるようになります。
AUO の場合、M4C は INPUT 構造体もインラインアセンブラも使っていないようなので C ソースには手をつけなくても済みます。しかし、Microsoft と Borland ではリンカのコマンドラインオプションがかなり違うので Makefile を大幅に修正しなければいけません。
変更前・変更後の Makefile を次に示します。
| 変 更 前 |
### for Borland C++ Compiler Setting #CC = bcc32 #CFLAG = -c -5 -K -O2 -Oc -OS -Ov #LINK = tlink32 #LFLAG = #RC = brcc32 ### for Microsoft Visual C Setting CC = cl CFLAG = /c /Ox /W4 /Zp1 RC = rc LD = link LFLAG = user32.lib vfw32.lib advapi32.lib /DEF:m4c.def /DLL /OUT:m4c.auo OBJ = m4c.obj check_block.obj filename.obj compressor.obj binary.obj bgr24.obj m4c.res ALL: m4c m4c: $(OBJ) $(LD) $(LFLAG) $(OBJ) m4c.obj: m4c.c ../filename.h ..\check_block.h ..\binary.h ..\bgr24.h resource.h $(CC) $(CFLAG) m4c.c check_block.obj: ..\check_block.c ..\check_block.h $(CC) $(CFLAG) ..\check_block.c compressor.obj: ..\compressor.c ..\compressor.h $(CC) $(CFLAG) ..\compressor.c filename.obj: ..\filename.c ..\filename.h $(CC) $(CFLAG) ..\filename.c binary.obj: ..\binary.c ..\binary.h $(CC) $(CFLAG) ..\binary.c bgr24.obj: ..\bgr24.c ..\bgr24.h $(CC) $(CFLAG) ..\bgr24.c m4c.res: m4c.rc resource.h $(RC) m4c.rc clean: DEL *.obj DEL *.res DEL *.lib DEL *.exp install: ALL copy m4c.exe $(BINDIR)m4c.exe |
| 変 更 後 |
### for Borland C++ Compiler Setting CC = bcc32 CFLAG = -c -5 -K -O2 -Oc -OS -Ov LD = ilink32 LFLAG = /Tpd LOPT = , m4c.auo, , c0d32.obj cw32mti.lib import32.lib, m4c.def, RC = brcc32 ### for Microsoft Visual C Setting #CC = cl #CFLAG = /c /Ox /W4 /Zp1 #RC = rc #LD = link #LFLAG = user32.lib vfw32.lib advapi32.lib /DEF:m4c.def /DLL /OUT:m4c.auo OBJ = m4c.obj check_block.obj filename.obj compressor.obj binary.obj bgr24.obj RES = m4c.res ALL: m4c m4c: $(OBJ) $(RES) $(LD) $(LFLAG) $(OBJ) $(LOPT) $(RES) m4c.obj: m4c.c ../filename.h ..\check_block.h ..\binary.h ..\bgr24.h resource.h $(CC) $(CFLAG) m4c.c check_block.obj: ..\check_block.c ..\check_block.h $(CC) $(CFLAG) ..\check_block.c compressor.obj: ..\compressor.c ..\compressor.h $(CC) $(CFLAG) ..\compressor.c filename.obj: ..\filename.c ..\filename.h $(CC) $(CFLAG) ..\filename.c binary.obj: ..\binary.c ..\binary.h $(CC) $(CFLAG) ..\binary.c bgr24.obj: ..\bgr24.c ..\bgr24.h $(CC) $(CFLAG) ..\bgr24.c m4c.res: m4c.rc resource.h $(RC) m4c.rc clean: DEL *.obj DEL *.res DEL *.lib DEL *.exp DEL *.ilc DEL *.ild DEL *.ilf DEL *.ils DEL *.map DEL *.tds |
一応変更を加えた行は太字で示しましたが、かなり変更点が多いので見落としがないように修正してください。Makefile の修正が終了すれば、AUO 版の M4C もコンパイル可能になります。コマンドライン版と同様に make を実行して m4c.auo を作成できます。
これでコマンドライン版、AUO 版ともにソースから作り直すことの可能な環境ができあがりました。次回からは M4C のカスタマイズです。
飲み会から帰ってきたら、スクライドの録画でドロップが発生していてかな〜り鬱になっていたり。ドロップ発生は今月2回目。これだから MiniDV テープは信頼性が……。そもそもメディアコンバータ機能はさっぱり使ってないし……。音はずれるし……。Y/C 分離はダメダメだし……。リモコンは使いづらいし……。ああ、WV-DR5 + 適当な S-VHS デッキにしておけば良かった。
という訳で時間がなくなったため、本当ならばネタの仕込みが間に合わない場合のために取っておくつもりだったものを最初から使うことにします。
m4c.c ファイルの中から、LOG_FORMAT_SCENE_CHANGE という文字が含まれている行を検索してください。次の行が最初に見つかるはずです。
#define LOG_FORMAT_SCENE_CHANGE "%6d %6d %s - seen changed (size %6d)\n" |
これはシーンチェンジ時のログを書き出す際のフォーマットです。フレーム番号と圧縮サイズ、キーフレームを挿入した理由が出力されるのですが……。seen change ってのはどうかと思います。(まあ何が言いたいのかは判るのですけど)
というわけで、正しく scene change とかになおしてあげてください。ただ、マクロ定義や変数名ではすべて、正しい scene になっているのに、何故かログに書き出すところだけ seen なんですよね。
今回はこれだけです。修正したら make を実行し、エラーなくコンパイルできるか、正常に動作するか、シーンチェンジ検出レベルを 2 程度にして動かし、ログを出力してみて、正しく変更されているかを確認しましょう。
こんなとろとろとしたペースに付き合ってられないという方や、もっと詳しく知りたいという方のために、C 言語と Win32API についての参考情報へのポインタを示しておこうかと思います。
私は C 言語を 平林 雅英「新 ANSI C 言語辞典」(1997, 技術評論社) を片手に、その辺で拾ったソースを読むことで覚えました。この方法が万人向けだとは思いませんが、もしも本を買うのでしたら、文法および関数のリファレンスとして使える本を買った方が良いと思います。何か適当なサンプルの作り方だけを示した本というのは(このシリーズと同様に)本に書いてあることと、少し違うことをやろうとしたときの参考にはなりません。その点、辞書的に使える本であればやりたいことと適合する機能を探すのに使うことができ、将来に渡って使うことができます。
C はそういう意味での良書が安価に、そこそこ多くあるのですが、Video for Windows API や DirectShow API などのいわゆる Win32API は、日本語の良書は乏しく、また高価です。仕方がないので、Platform SDK Update Site から Platform SDK を入手し、英語と格闘するしかありません。Visual C++ や MSDN を購入すれば日本語の Platform SDK マニュアルも入手できるのですが、英語版と比較するとやはり不十分です。諦めて辞書や翻訳サイトを利用する覚悟を決めてください。
色タイミング補正プラグイン、バグ修正の更新しています。AUF からどうぞ。もりのみやこさん、バグ報告ありがとうございました。
まずお詫びから。前々回の 作り方 AUO 編 での方法では重要なステップがひとつ抜けていました。m4c.rc ファイル 3 行目の「#include "winres.h"」で、brcc32 が "winres.h" が開けないと言って make が中断してしまったと思います。
この行は Microsot のリソースコンパイラ rc では必要な行なのですが、Borland の brcc32 では不要です。次のように修正してください。
| 前 |
#include "winres.h" |
| 後 |
#ifndef WORKSHOP_INVOKED #include <winres.h> #endif |
この修正を加えれば、AUO 版も正常に作成できるようになります。(しかし bcc32 では %INCLUDE% を読まないくせに、なんで brcc32 だと読むのだろう。くすん)
M4C では、デルタフレームの最大値を設定することでシーンチェンジを検出できるようになっています。詳しいことは省きますが、3920 の MS MPEG4 V2 では高レートを与えている場合、シーンチェンジ時などの動き補償が効かないフレームでデルタフレームのサイズが大きくなります。これは M4C のログを眺めてみると判りやすいです。
ファイルサイズを抑えたい場合、このシーンチェンジ検出は非常に有効なのですが、シーンチェンジオプションから「幅×高さ×オプション値/16」という式を使って実際の制限サイズを出しているため微妙な調整がしにくくなっています。もう少し細かく調整したい場合はこの式を弄ればそれが可能になります。AUO 版の場合は 231 行目、コマンドライン版の場合は 378 行目を見てください。
p->delta_frame_max_size = (frame_format->biWidth * frame_format->biHeight / 16) * opt->scene_change_detector; |
ここにダイレクトに 16 と書いてあるので、これを 32 や 64 など適当な値に変更してあげてください。これでより細かな制御が可能になるのですが、AUO 版の場合、シーンチェンジ検出オプションで設定可能な最大値が 10 に制限されていて使いづらくなっています。これは 523 行目で設定されているのでそれを修正しましょう。変更前後で次のようになります。
| 前 |
SendDlgItemMessage(hdlg, IDC_SPIN8, UDM_SETRANGE, 0, 10); |
| 後 |
SendDlgItemMessage(hdlg, IDC_SPIN8, UDM_SETRANGE, 0, 20); |
変更後の 20 というのはあくまでも例です。ただし、フレームサイズの式での分母を 64 にした場合でもほぼ十分な検出レベルが設定可能な値として選びました。
コマンドライン版では -s オプションの上限値が制限されていないため、特に変更を加えずに自由に設定することができます。
さて、多くの人が待ち望んでいるであろう最適化に入ります。流石にこれは1回では終わらないので4回に分けます。MMX 化までやる予定ですのでがんばって付いてきてください。
M4C 内部で一番処理が重いのはノイズの検出です。この処理は README にも書いてあるとおり、src\check_block.c で行われています。
オリジナルのソースでは、check_block.c 内には次の3つの関数が存在します。
| 関数名 | 機能 |
| check_block() |
8x8 ブロック毎に is_noise() を呼び出し、ノイズと判定されれば発生位置を返す m4c() ルーチンから直接呼ばれる グローバル関数 |
| RGB_to_Y() |
1 画素を RGB 値から Y(グレースケール)に変換する is_noise() および、bad_block_report() から呼ばれる グローバル関数 |
| is_noise() |
8x8 ブロックを比較し、ノイズの判定を行う ファイルローカル関数 |
この中で一番重いのは RGB_to_Y() 関数なのですが、1 画素を RGB から Y に変換するだけの関数というのは非常に MMX 化しづらいです。また 1 画素毎に関数を呼ぶのは非常にオーバヘッドが大きく速度低下の原因になっています。
RGB_to_Y() 関数は他のルーチンからも呼ばれる関数なのでそのまま残しておき、今回は is_noise() 関数をより MMX 化しやすい形に作り変えることにします。(注:同じ機能をもつ複数の関数が存在するのはバグの温床となるため、本来ならば避けた方が良いです)
まず、is_noise() 関数は次のように作り変えます。
/* SIMD 化を目的として、is_noise 関数を分割、インターフェースも変更 */
static int is_noise(unsigned char *rgb1, unsigned char *rgb2, int step, int diff, int pixel)
{
int ret;
void *yo;
short *y1;
short *y2;
int work;
/* 後の為に 8 byte alignment をとっておく */
yo = malloc(sizeof(short)*8*8*2+8);
work = (int)yo;
work += 8;
work -= work & 0x7;
y1 = (short *)(void *)work;
y2 = y1 + 8*8;
block_RGB_to_Y(rgb1, y1, step);
block_RGB_to_Y(rgb2, y2, step);
ret = block_compare_Y(y1, y2, diff, pixel);
free(yo);
return ret;
} |
ここで block_RGB_to_Y() および、block_compare_Y() という2つの新しい関数を使っています。それぞれ 8x8 の RGB -> Y 変換と 8x8 ブロックでの Y 比較を行うものですが、オリジナルのソースには無いものなので追加してあげなければいけません。
関数を新規に作成する場合、ソースファイルの先頭近くでプロトタイプ宣言を行います。具体的には、次のようになります。
static int is_noise(unsigned char *rgb1, unsigned char *rgb2, int step, int diff, int pixel); static void block_RGB_to_Y(unsigned char *rbg, short* y, int step); static int block_compare_Y(short *block1, short *block2, int diff, int pixel); |
ここでは、is_noise() 関数のプロトタイプ宣言の次に、新規に作成した2つの関数のプロトタイプ宣言を書いています。また is_noise() 関数も一部引数を変更しているので、その修正もしています。
次に関数の実装部を作成します。それぞれ次のようになります。
/* 8x8 ブロックの RGB -> Y 変換 */
static void block_RGB_to_Y(unsigned char *rgb, short* y, int step)
{
int i,j;
int work;
for(i=0;i<8;i++){
for(j=0;j<8;j++){
work = rgb[i*step+j*3+0] * 7471; /* B * 0.114 */
work += rgb[i*step+j*3+1] * 38469; /* G * 0.587 */
work += rgb[i*step+j*3+2] * 19595; /* R * 0.299 */
work += (1<<16)-1; /* 切り上げ */
y[i*8+j] = (short)(work >> 16);
}
}
}
static int block_compare_Y(short *block1, short *block2, int diff, int pixel)
{
int i;
int count;
count = 0;
for(i=0;i<(8*8);i++){
if(abs(block1[i]-block2[i]) >= diff){
count += 1;
}
}
return (count >= pixel);
} |
さて、残りは is_noise() 関数の引数を変更したので、その呼び出し側である check_block() 関数の修正です。が、その前に一応説明しておきます。修正版での step はオリジナル版での up に相当します。そして、オリジナルにはあった right は消えて固定値 3 のハードコーディングになっています。(ハードコーディングもバグの温床になりやすいので避けた方が良いです)
オリジナルではおそらく RGB 888 以外にも対応しようというつもりがあって 画素の幅(byte)を算出し、right として is_noise() に渡していたのでしょうが、実際 RGB 565 や RGB 555 に対応しようとすると right だけでは足りず、また VFAPI では RGB 888 固定であり、VfW でも RGB 888 が標準になっているので、残しておくと最適化の際に邪魔になるだけだと考えて削除しました。
修正後のコードは次のようになります。
int check_block(LPVOID original, LPVOID result, BITMAPINFOHEADER *format, int diff, int pixel)
{
int i,j,n;
unsigned char *rgb1, *rgb2;
int step;
int r;
int mcu_h_number, mcu_v_number;
rgb1 = (char *)original;
rgb2 = (char *)result;
step = format->biWidth * 3;
mcu_h_number = format->biWidth / 8;
mcu_v_number = format->biHeight / 8;
n = (format->biWidth % 8);
rgb1 += step * n;
rgb2 += step * n;
for(i=0;i<mcu_v_number;i++){
for(j=0;j<mcu_h_number;j++){
if(is_noise(rgb1+(i*8*step+j*8*3), rgb2+(i*8*step+j*8*3), step, diff, pixel)){
r = (i*8+n) << 18;
r += ((j*8) << 2);
r += 1;
return r;
}
}
}
return 0;
} |
以上で修正は終了です。まだ MMX 化は行っていないのでそれほど速くなっていることは期待できませんが、1画素毎の関数呼び出しというオーバヘッドは消えているはずです。試しに前回までに作成した M4C.EXE と今回の M4C.EXE で速度の比較をしてみましょう。
私の環境では、次の結果になりました。(-s オプションの式は分母を 64 にしています)
D:\work>m4c -r6000 -k20 -d11 -p32 -s12 shippo_cm.aup old.avi frame: 900/ 900, rest time: 00:00:00, estimate size: 5.027 M finish!! total time: 00:02:52 D:\work>m4c -r6000 -k20 -d11 -p32 -s12 shippo_cm.aup step_1.avi frame: 900/ 900, rest time: 00:00:00, estimate size: 5.027 M finish!! total time: 00:02:50 |
とこのようにあまり速くなりませんでしたが、遅くはならずに済んだようです。次回はアセンブラです。
今回から SIMD 化に入ります。しかし、FREE 版 BCC にはアセンブラが付属していないため、インラインアセンブラを使用して C のソース中にアセンブラコードを書くことができません。(書いてもコンパイルできません)
仕方が無いので、無料で入手可能な MASM を使用し ASM ファイルからアセンブルしてオブジェクトファイルを作り、それをリンクさせることで SIMD 版 M4C を作成することにします。
まず MASM のインストールです。Microsoft から Win98 DDK および MASM 6.1x to 6.14 patch を入手してください。(このリンクは 9/26 のものです)
ダウンロードが完了したら、まず 98DDK.EXE を実行し DDK のインストールを行います。このとき、途中でどのパッケージをインストールするか聞かれますが、MASM は Build Environment を選択するだけでインストールされます。インストールが成功した場合、インストール先フォルダに「bin\win98」というフォルダがあり、その中に ML.EXE が存在しているはずです。この ML.EXE が MASM の実行ファイルなので、これが見つからない場合はもう一度 98 DDK のインストールをやり直してください。
bin\win98 (デフォルトでは C:\98DDK\BIN\WIN98)フォルダに ML.EXE が見つかったら、ML.EXE と ML.ERR を選択し、BCC をインストールしたフォルダの BIN (デフォルトでは C:\Borland\bcc55\BIN)にコピーします。
次に実行するのは MASM のアップデートです。MASM の最新版は 6.15 が VC Processer Pack として存在するのですが、これは VC のインストールされていない環境で実行するにはかなりがんばる必要があります。ので、通常のパッチとして配布されている最新版である MASM 6.14 を使います。6.14 と 6.15 の違いは SSE2 のサポートのみであるため SSE2 を使わないのであれば特に 6.15 を入手する必要はありません。
MASM 6.14 パッチの当て方ですが、まず ML614.exe を適当な新規フォルダにコピーしてから実行します。すると、幾つかのファイルが作成されるはずです。次に、作成されたファイルの中から patch.exe と patch.rtd, patch.rtp を選択し、BCC のインストール先フォルダ(デフォルトでは C:\Borland\bcc55)にコピーします。コピーしたら patch.exe を実行してください。DOS 窓(NT 系ではコマンドプロンプト)が開きパッチの状況が表示されるはずです。
パッチが問題なくあたると、DOS 窓の表示は次のようになるはずです。
トトトトト Patch File Processing Complete トトトトト トトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトト - Results of Application of Patch File - トトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトト File Patches Applied ......................... ( 2) Files Modified .................. ( 2) Files Renamed. .................. ( 0) Files Added ..................... ( 0) Files Deleted ................... ( 0) File Patches Skipped (New Files Up-To-Date)... ( 0) File Patches Ignored (Old Files Missing)...... ( 0) トトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトト Total File Patches Processed ................. ( 2) トトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトトト |
パッチが正常にあたれば、patch.exe および patch.rtd, patch.rtp は消してしまって構いません。これで MASM のインストールは完了です。本当ならば INC ファイルを適当なフォルダにコピーして環境変数 INCLUDE を設定した方がよいのですが、MMX/SSE コードをつつくだけであればそれは実行しなくても問題ありません。
さて、早速 MMX を使ってみましょう。check_block_simd.asm をダウンロードして、M4C のソースフォルダ(check_block.c があるフォルダです)にコピーしてください。
次に、Makefile を次のように変更してください。
### for Borland C++ Compiler Setting CC = bcc32 CFLAG = -c -5 -K -O2 -Oc -OS -Ov LFLAG = ASM = ml AFLAG = /c /DBCC ### for Microsoft Visual C Setting #CC = cl #CFLAG = /c /G5 /O2 /Gr /J #ASM = ml #AFLAG = /c /coff #LFLAG = vfw32.lib advapi32.lib ### command install directory BINDIR = C:\windows\command\ OBJ = m4c.obj check_block.obj vfapi_read.obj vfw_read.obj filename.obj compressor.obj binary.obj bgr24.obj check_block_simd.obj ALL: m4c m4c: $(OBJ) $(CC) $(LFLAG) $(OBJ) m4c.obj: m4c.c filename.h check_block.h vfapi_read.h vfw_read.h vfapi.h binary.h bgr24.h $(CC) $(CFLAG) m4c.c check_block.obj: check_block.c check_block.h $(CC) $(CFLAG) check_block.c vfapi_read.obj: vfapi_read.c vfapi_read.h vfapi.h $(CC) $(CFLAG) vfapi_read.c vfw_read.obj: vfw_read.c vfw_read.h $(CC) $(CFLAG) vfw_read.c compressor.obj: compressor.c compressor.h $(CC) $(CFLAG) compressor.c filename.obj: filename.c filename.h $(CC) $(CFLAG) filename.c binary.obj: binary.c binary.h $(CC) $(CFLAG) binary.c bgr24.obj: bgr24.c bgr24.h $(CC) $(CFLAG) bgr24.c check_block_simd.obj: check_block_simd.asm $(ASM) $(AFLAG) check_block_simd.asm clean: DEL *.obj DEL *.tds install: ALL copy m4c.exe $(BINDIR)m4c.exe |
これはコマンドライン版の Makefile ですが、AUO 版の場合は次のようになります。
### for Borland C++ Compiler Setting CC = bcc32 CFLAG = -c -5 -K -O2 -Oc -OS -Ov LD = ilink32 LFLAG = /Tpd LOPT = , m4c.auo, , c0d32.obj cw32mti.lib import32.lib, m4c.def, ASM = ml AFLAG = /c /omf /DBCC RC = brcc32 ### for Microsoft Visual C Setting #CC = cl #CFLAG = /c /Ox /W4 /Zp1 #RC = rc #LD = link #LFLAG = user32.lib vfw32.lib advapi32.lib /DEF:m4c.def /DLL /OUT:m4c.auo #ASM = ml #AFLAG = /c /coff OBJ = m4c.obj check_block.obj filename.obj compressor.obj binary.obj bgr24.obj check_block_simd.obj RES = m4c.res ALL: m4c m4c: $(OBJ) $(RES) $(LD) $(LFLAG) $(OBJ) $(LOPT) $(RES) m4c.obj: m4c.c ../filename.h ..\check_block.h ..\binary.h ..\bgr24.h resource.h $(CC) $(CFLAG) m4c.c check_block.obj: ..\check_block.c ..\check_block.h $(CC) $(CFLAG) ..\check_block.c compressor.obj: ..\compressor.c ..\compressor.h $(CC) $(CFLAG) ..\compressor.c filename.obj: ..\filename.c ..\filename.h $(CC) $(CFLAG) ..\filename.c binary.obj: ..\binary.c ..\binary.h $(CC) $(CFLAG) ..\binary.c bgr24.obj: ..\bgr24.c ..\bgr24.h $(CC) $(CFLAG) ..\bgr24.c check_block_simd.obj: ..\check_block_simd.asm $(ASM) $(AFLAG) ..\check_block_simd.asm m4c.res: m4c.rc resource.h $(RC) m4c.rc clean: DEL *.obj DEL *.res DEL *.exp DEL *.lib DEL *.ilc DEL *.ild DEL *.ilf DEL *.ils DEL *.map DEL *.tds |
最後に、check_block.c の書き換えです。まず、block_RGB_to_Y() のプロトタイプ宣言を次のように書き換えます。
| 前 |
static void block_RGB_to_Y(unsigned char *rbg, short* y, int step); |
| 後 |
extern void __stdcall block_RGB_to_Y(unsigned char *rbg, short* y, int step); |
そして、block_RGB_to_Y() の実装部は全て削除してしまってください。これで準備は全て完了です。make を実行すれば RGB -> Y 変換に MMX コードを使用するバージョンの M4C(スパゲッティ)が手に入ります。
MMX 対応でどの程度速くなるかというと、私の環境では次の結果になりました。
D:\work>m4c -r6000 -k20 -d11 -p32 -s12 shippo_cm.aup old.avi frame: 900/ 900, rest time: 00:00:00, estimate size: 5.027 M finish!! total time: 00:02:43 |
900 フレームで初期状態のプログラムと比較して約 9 秒の短縮。30000 フレームであれば約 5 分速く処理できる計算です。確かに速くなってはいるのですが、労力に見合うだけの速度向上と言えるかはちょっと疑問です。
それはそれとして、次回は、今回配布した check_block_simd.asm ファイルの MMX コード部について解説する予定です。
前回配ったアセンブラソース MMX コード部の解説をします。変換コア(前半4画素)部分のソースを追っていくので、不明な命令があれば「IA-32 インテル・アーキテクチャ・ソフトウェア・デベロッパーズ・マニュアル 中巻:命令セット・リファレンス」を引きながら読んで下さい。
movd mm0, [esi] ; 00_00_00_00_B2_R1_G1_B1 movd mm1, [esi+4] ; 00_00_00_00_G3_B3_R2_G2 movd mm2, [esi+8] ; 00_00_00_00_R4_G4_B4_R3 |
まずここでは4画素分のデータを読み込んでいます。8 byte アライメントが取れている場合ならば movq で 8 byte を一度に読みこんだ方が速いのですが、VfW から渡されるデータは 4 byte アライメントしか保証されていないので movd での 4 byte づつの読み込みになっています。
24 bit RGB データは、メモリ内に BGRBGRBGR の順で並んでいますが、Intel 系 CPU ではリトルエンディアンを採用しているため、MMX レジスタに読みこんだ結果はコメント欄に書いた形式になります。RGB は各色要素を、1234 はどの画素のデータかを示しています。
punpcklbw mm0, mm3 ; 00B2_00R1_00G1_00B1 punpcklbw mm1, mm3 ; 00G3_00B3_00R2_00G2 punpcklbw mm2, mm3 ; 00R4_00G4_00B4_00R3 |
ここで、読みこんだ 8 bit データを 16 bit に拡張しています。RGB -> Y 変換では乗算が必要なのですが、Intel の整数 SIMD 命令では 16 bit データに対してしか乗算を実行することができない(pmuludq は除く)ためです。
mm3 レジスタはこのルーチンの先頭で pxor 命令を使用して 0 に初期化してあるため、実行後の各レジスタはコメント欄に書いた形式になります。
movq mm4, mm0 ; 00B2_00R1_00G1_00B1 movq mm5, mm2 ; 00R4_00G4_00B4_00R3 psrlq mm4, 48 ; 0000_0000_0000_00B2 psllq mm5, 32 ; 00B4_00R3_0000_0000 por mm4, mm5 ; 00B4_00R3_0000_00B2 |
ここでの目的は「00B4_00R3_0000_00B2」という形式のデータを作成することです。この次のステップで pmaddwd 命令を使用して色要素と係数の乗算および計算結果の和算を実行するのですが、B2 は1画素目のデータと同じレジスタに、R3 は4画素目のデータと同じレジスタに存在するためこのまま計算することができません。
そこで「00B4_00R3_0000_00B2」という形式にコピーしておきます。R3 と B2 をこの順にしたのは「00B2_00R1_00G1_00B1」と同じ係数を使用して pmaddwd を使えるようにするためです。
pmaddwd mm0, _0_R_G_B ; 00000YR1_0000YGB1 pmaddwd mm1, _G_B_R_G ; 0000YGB3_0000YRG2 pmaddwd mm2, _R_G_B_0 ; 0000YRG4_00000YB4 pmaddwd mm4, _0_R_G_B ; 00000YR3_00000YB2 |
ここからが実際の変換処理です。pmadwd を使い、色要素に Y 変換用の係数を掛けて足し合わせます。違う画素の色要素が隣にある場合は係数に 0 を選び、足されても問題が無いようにしています。
計算結果はコメントとして書いたとおりなのですが、この読み方は YR1 の場合、1画素目の R 要素に係数を掛けたものという意味で、YGB1 は1画素目の G と B に係数を掛けて足したものという意味で書いています。
同様に YGB3 は3画素目の G と B に係数を掛けて足したもの、YRG4 は4画素目の R と G に係数を掛けて足したものという意味です。
movq mm5, mm0 ; 00000YR1_0000YGB1 movq mm6, mm2 ; 0000YRG4_00000YB4 psllq mm0, 32 ; 0000YGB1_00000000 psrlq mm2, 32 ; 00000000_0000YRG4 |
ここでは1レジスタに存在している1画素目データと4画素目のデータを paddd で足せるように2つのレジスタに分けて位置を調整しています。
ここの4命令は SSE が使える場合ならば2つの pshufw 命令に置きかえる事ができます。
paddd mm1, mm4 ; 000YRGB3_000YRGB2 paddd mm0, mm5 ; 000YRGB1_0000YGB1 paddd mm2, mm6 ; 0000YRG4_000YRGB4 |
この paddd で Y は全て完成します。mm0 の上位 32 bit に1画素目の Y が、mm1 の下位 32 bit に2画素目の Y が、上位 32 bit に3画素目の Y が、mm2 の下位 32 bit に4画素目の Y が作成されます。
ただし、ここで作成された Y は固定小数点演算の(通常よりも 15 bit 大きな)Y です。次からのステップでこの Y を通常の 8 bit データに落として、また出力用にデータを整列しなおします。
punpckhdq mm0, mm1 ; 000YRGB3_000YRGB1 punpckldq mm1, mm2 ; 000YRGB4_000YRGB2 paddd mm0, _32767 ; 切り上げ paddd mm1, _32767 ; 〃 psrld mm0, 15 ; 000000Y3_000000Y1 psrld mm1, 15 ; 000000Y4_000000Y2 |
ここで、3つのレジスタに分かれていたデータを2つのレジスタにまとめ、切り上げ用のデータを足してから 15 ビット右シフトすることで 8 bit の Y にしています。
psllq mm1, 16 ; 00Y4_0000_00Y2_0000 por mm0, mm1 ; 00Y4_00Y3_00Y2_00Y1 |
今までの計算で、mm0 には Y3 と Y1、mm1 に Y4 と Y2 となるように調整していたため、Y を整列させるには mm1 を 16 bit 左シフトしてから mm0 と OR を取れば済むだけになっています。
ここでは出力データが正しく並ぶように調整していますが、M4C だけで考える場合、RGB と Y が1対1で対応し、位置が固定であればブロックノイズの検出には影響が出ないためより最適化することも可能です。
movq [edi], mm0 ; Y を出力 |
最後に Y をレジスタからメモリに書き出しています。これで4画素についての処理は終わり、残りの4画素についても同様に計算します。
以上の処理を全部で8行分おこなえば 8x8 ブロックの RGB -> Y 変換は終了します。これが、前回配布した ASM ファイルの詳細です。
解説の中で幾つか触れましたが、このアセンブラコードは MMX の拡張機能しか使用しておらず、SSE を使うか、より効率の良いコードの配置を行うなどでまだまだ速度を向上させる余地があります。興味のある人は挑戦してみてください。
次回は残った block_compare_Y の SIMD 化を行います。
今回は block_compare_Y() の SIMD 化を行います。こちらは RGB -> Y 変換ほどの速度向上を期待できませんが、それでも絶対値の算出や比較部分等、SIMD による最適化が有効そうな部分なので試してみました。
check_block_simd.asm(注:ファイルにミスがあったため 9/30, AM 1:40 に修正)を前回と同様にダウンロードし、M4C のソースフォルダに置いてください。
今回は Makefile の修正は必要ありません。必要なのは check_block.c の書き換えだけです。まず、block_compare_Y のプロトタイプを書き換えます。
| 前 |
static int block_compare_Y(short *block1, short *block2, int diff, int pixel) |
| 後 |
extern int __stdcall block_compare_Y(short *block1, short *block2, int diff, int pixel); |
block_compare_Y の実装部はすべて削除してください。後は make をすれば、輝度の比較部分も MMX 化した M4C が完成します。
今回配布した check_block_simd.asm ファイルから、block_compare_Y() のポイント部分を解説していきます。
movd mm1, [esp+12+12]
; 0000_0000_0000_diff
punpcklwd mm7, mm7 ; 0000_0000_diff_diff
punpcklwd mm7, mm7 ; diff_diff_diff_diff
psubw mm7, _pw1 ; > を >= と同じにするため
|
まずは「下準備」部分から。ここではパラメータとして渡された diff を 16bit × 4 の形式に変更して mm7 にコピーしています。MMX ではこれを punpcklwd を2回呼び出すことで実行していますが、SSE が使用可能な場合この2命令を1つの pshufw に置き換えることが可能です。
movq mm1, [esi] ; 00Y4_00Y3_00Y2_00Y1 movq mm2, [esi+8] ; 00Y8_00Y7_00Y6_00Y5 movq mm3, [edi] ; 00y4_00y3_00y2_00y1 movq mm4, [edi+8] ; 00y8_00y7_00y6_00y5 lea esi, [esi+16] ; アドレスインクリメント lea edi, [edi+16] ; 〃 movq mm5, mm1 ; 00Y4_00Y3_00Y2_00Y1 movq mm6, mm2 ; 00Y8_00Y7_00Y6_00Y5 psubusw mm1, mm3 ; 飽和演算で差を取る psubusw mm2, mm4 ; psubusw mm3, mm5 ; 逆方向でも差を取る psubusw mm4, mm6 ; por mm1, mm3 ; 差の絶対値にする por mm2, mm4 ; |
ここでは2つのメモリブロックから 8 つずつ Y を読み込み、差の絶対値を取っています。これは「インテル・アーキテクチャ最適化マニュアル」に掲載されている方法を使用しています。
SSE が使用可能な場合 psadbw という「差の絶対値を求めてすべてを足しあわせる」という命令があります。これをうまく使用するとかなりの高速化が期待できるのですが、これは M4C のノイズ検出アルゴリズムとの相性が悪く、使うことができません。
目立つノイズのみ除去できれば十分だという場合には、RGB -> Y 変換も止めてしまい PSADBW を使用して絶対差の累積を計算、平均を取って指定値以上であればノイズと判定するようにアルゴリズム自体を変更することで、高速化が可能です。(レベルを下げた場合の誤検出率が上がるので、微妙なノイズを除去できなくなってしまいますが)
pcmpgtw mm1, mm7 ; diff との比較 pcmpgtw mm2, mm7 ; 大きい場合 -1 (FFFF) paddw mm0, mm1 ; 結果を足していく paddw mm0, mm2 |
ここでは、前回のステップで作成した差の絶対値と最初に作成した diff を pcmpgtw で比較し、結果を mm0 に足しています。
pcmpgtw で比較すると、デスティネーションオペランド(注:pcmpgtw mm1, mm7 とある場合の mm1。mm7 はソースオペランドと呼ばれる)の 16 bit 整数がソースオペランドよりも大きい場合に 0xFFFF が入ります。これは符号付き 16 bit で考えると -1 に相当するので、diff よりも差の大きい Y があると、mm0 は -1 づつ増えていきます。
この処理を 8 回繰り返すと、64 個について、比較結果がすべて mm0 に格納されます。それを評価するのが次のステップです。
pxor mm1, mm1 ; 0 で初期化
pxor mm2, mm2
psubw mm1, mm0 ; 正負反転
movq mm3, mm1
punpcklwd mm1, mm2 ; 0000cnt2_0000cnt1
punpckhwd mm3, mm2 ; 0000cnt4_0000cnt3
paddd mm1, mm3 ; count4+2_count3+1
movq mm0, mm1
psrlq mm0, 32 ; 00000000_count4+2
paddd mm0, mm1 ; count4+2_c4+3+2+1
movd ecx, mm0 ; c4+3+2+1
xor eax, eax
cmp ecx, [esp+12+16]
; pixel と比較
setge al ; 大きければ al をセット
|
ここまで計算されている mm0 は diff よりも大きい画素がある毎に -1 づつ足されたものなので、マイナスの数値になっています。pixel と比較するためには符号を揃える必要があります。ので、0 から引いています。
後は、1レジスタに 4 つ入っているのを、別のレジスタにばらしてから足していき、最終的には 32bit レジスタに書き出します。ここではループカウンタで使用していた ecx に書き出しています。
あらかじめ eax をクリアしておき、ecx を pixel と比較、大きければ al レジスタ(eax の下位 8bit レジスタ)に setge でビットをセットします。これは int (32bit 整数) を返す関数の場合、戻り値は eax レジスタにセットして受け渡すことになっているからです。
まだまだ終わっていない、もっと最適化できる――例えば「RGB -> Y の最後、1レジスタにまとめる所はあんな面倒な位置調整しないで、普通は packusdw とか使わない?」――とか言われそうですが、SIMD 化に関してはここで終了することにします。次回は M4C とは無関係なネタを扱いますが、その次は M4C に戻って、最適化について頂いたメールを紹介する予定です。
PSADBW と動き検索について書きます。MPEG の圧縮原理に興味が無い方には退屈かもしれません。
PSADBW という命令が Pentium III や K6-III などの IA-32 プロセッサに搭載されています。これは MMX/SSE レジスタを使用して 8 bit データの差の絶対値を計算し、足し合わせる命令です。想定される用途は MPEG 圧縮時の動き検索です。ほぼ、そのためだけに用意されている命令と言って良いでしょう。
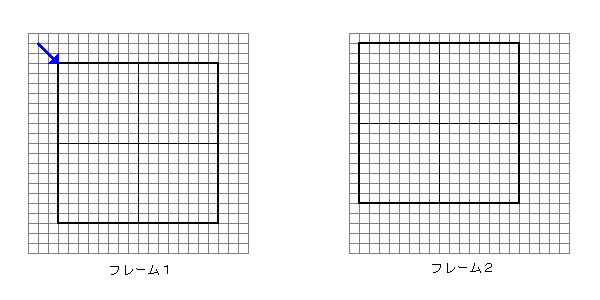
MPEG 圧縮の動き検索とは、16x16 ブロック(マクロブロック)で前後のフレームから最も一致する場所を探し出す処理です。次の図1を見てください。
|
| 図1 MPEG の動き検索モデル |
ここでフレーム1は参照先フレーム、フレーム2が参照元フレームです。フレーム2を 16x16 サイズに区切った後のとあるブロック(太線部分)に注目した場合にフレーム1の中からフレーム2のブロックに一番似た部分を検索するのが動き検索です。フレーム1の太線部分で示したブロックが最も似ていた場合、フレーム2のブロックからフレーム1で検索されたブロックへのずれ(青の矢印)を動きベクトルとして記録し、差分画像を取って圧縮していきます。
動き検索では少しずつブロックを動かしながら一致度を計算し、最も一致度が高い場所を動きベクトルとして採用します。そこで問題になるのは一致度の判定方法です。
比較的シンプルな一致度の検出方法は、相違量を計算して比較する方法です。ブロック間で各画素毎に差分の絶対値を取り、それを足し合わせたものを相違量として、これが一番低いものを動きベクトルとして採用する計算方法です。この計算方法はまさしく PSADBW 命令そのものです。
このアルゴリズムを採用すると計算はシンプルになり、対応 CPU であれば PSADBW 命令を使用して非常に高速、かつ簡単に動き検索を実行できます。しかし問題が無いわけではありません。このアルゴリズムが問題になるのはフェードの場合です。次の図2の場合について考えてみます。
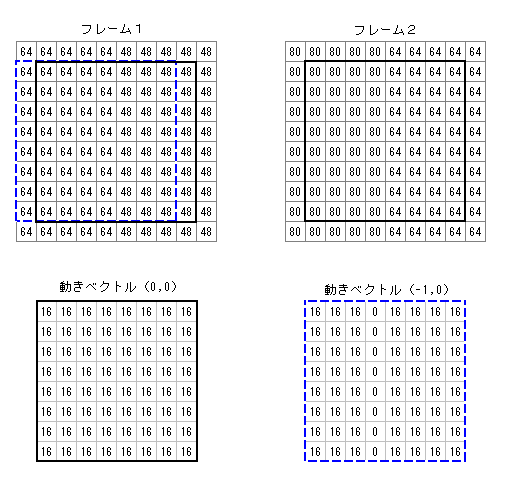 |
| 図2 フェードの場合 |
この場合もフレーム1が参照先でフレーム2が参照元です。上段がオリジナル(フレーム2はフレーム1のデータが 16 増えたもの)で、下段は動きベクトルとして(0,0)を採用した場合(黒線枠)の差分データと(-1,0)を採用した場合(青波線)の差分データです。本来ならば 16x16 のブロックで考えるのが正しいのですが、作図の都合上 8x8 のブロックになっています。
動きベクトルとして(0,0)を採用したブロックの場合、差分の絶対値を全て足し合わせたものは 1024 となりますが、動きベクトルとして(-1,0)を採用した場合は 896 となり、(-1,0)の方が一致度が高く(相違度が低く)こちらを採用した方が良いという結果になっています。
しかし、実際に DCT を実行すると、差分データ全てが 16 の動きベクトル(0,0)の場合は DC 係数1つで表現できるのに対し、(-1,0)の場合は水平方向の AC 係数が複数必要となり必要データ量が増えます。CQ 等の VBR では圧縮率が悪くなり、CBR では画質が低下します。
この問題を避ける為には動き検索の際に差分データの DCT まで実行し、必要データ量を測定して判定するのが最良なのですが、それを実行すると MPEG 圧縮が現実的な時間内で終了しなくなります。しかし差分データを求めた後絶対値の和を比較する前に、差分データの最大値と最小値の差を比較しそれが小さければより適切な動きベクトルであると判定するアルゴリズムならば、それほど遅くはなりません。
またそのための命令も PMAXSW, PMINSW が(SSE & Enhanced 3DNow! ですが)用意されています。エンコード速度を重視する場合であれば PSADBW を使うのも良いかもしれませんが、画質(および圧縮率)を重視する場合はあまり望ましい動き検索アルゴリズムでは無いと考えます。
M4C の話はネタが間に合わなかったので月曜になる予定です。その際は Makefile および今までに変更を加えたソース一式も配布します。バイナリの配布は行いませんので悪しからず。あと、28 日に配布したアセンブラソースにはミスがありアセンブルできないはずです。修正版に差し替えてあるので、落しなおしてください。
28 日に OCV の増速が行われたので、今の M1 は下り 3Mbps 上り 512kbps になってます。ひょっとしたら多少 M1 が軽くなったかもしれません。
まーそれはそれとして普通にダウンロードしてて 300 k byte/sec で落ちてきてくれるのは非常に快適です。やっぱり競争は重要ですね。ありがとう YahooBB。月額基本料も安くなってくれたのでかなり助かってます。
ユーザ数が少ないからなんでしょうけど、今の仕事先よりも遥かにネットワーク的に快適だったりします。住んでるところだと 9.6kbps だけしか通っていないため、比べること自体が間違ってたり。
AirH" も速度は 32kbps でも構わないからもっと安くなってくれれば(ISP 料金込みで月 5000 を切ってくれれば)考えるのですけど……、7000 を超えてる現状だとちょっと利用できないですね。