土日に更新が無かった理由が「Fate/stay night」にあるとか言ったらやはり怒られてしまうのだろうか。実際のところまだ入手していないので、更新が無かった理由はちがうのだけど。
さて、本題。やっつけ仕事2号として、登録名やパスワードの変更やら ID の別名義への登録変更機能とかを公開しようかと考えていたのだけど、問題点発覚。チーム制の為にユーザ名やパスワード公開しているところでは、ユーザ名やパスワードが変え放題になってしまう。というわけでどうしようか悩んでいるところ。
既にテスト段階に入っているのにアレだけれども、表示名やらパスワードの変更機能はお蔵入りさせてしまうしかないのかも。ID の登録変更機能だけで公開するしかないのかなー。
チーム結成他は好きなようにしてください。サーバ負荷に関しては、何とかしなきゃいけないところなのですけど、今のところ対策が思い浮かばないのが悲しい点です。
サーバマシンは Celeron 1.7G & MEM 128M という微妙なスペックのものなのですが、回線状況や電源周りの安定性に関して一番まともな場所に置かれているものなので、あっさりと置き換えとかができないのですね。(マシン自体は sakura.ad.jp の大阪 NOC に置いてある)
このままで良いとは思っていないのですが、とりあえず思いつく対策は地道なボトルネック調査と焼け石に水な最適化程度です。
焼け石に水な最適化開始。とりあえず current.png の更新頻度を 60 秒に一回に落として、ID の無効化の条件を 1 週間以上報告無しから 24 時間経過してブロック数が 0 へと切り詰め。予想はしていたが殆ど効果が無いのが悲しい。
c2bf のクライアント側を動かしている機械でよりスペックの高いものに置き換えといったところで、自宅のネットワーク環境は信頼できない (月に一度は 1 時間程度メンテナンスとして通じなくなる時がある) ので不可になるし……追加出費は嫌だなー。
えー Frozen-Layer の某メインフレームマシンが話題になっているようですが、参加方法としては 0xffffff ブロックからデクリメントする形で動かしてみて、正解が見つかったらメール報告するという形しか思い浮かびません。
c2bf のクライアント改造が必要になるかと思いますが、やる気があるのでしたら試してみてください。
昨日、二度ほど "body[0] = ng", "error - failed on report()" とログに表示されて停止されていた方。もしオーバークロッキングをしているようでしたら、止めてください。オーバークロック等せずにそれが発生している場合は、環境の詳細等教えてください。
2/3 の 14:00 以降に "body[0] = ng" が出た場合は無視してください。それは client 側の問題ではなく、無人で 15 秒単位のリトライを続けるクライアントを黙らせる為にサーバ側で不正に返した答えですので、クライアント側には問題がありません。
今回のサーバダウンはクライアントを作成した際に考え無しなリトライインターバルを設定してしまったために、サーバ側の負荷が増大した際に復帰できずそのまま行列が伸び続けていってしまうために発生しました。サーバマシン増強を考えなければいけないのですが、マシンの手配に最短でも 10 日ほどかかりそうなので今後の対策をどうしようか考えているところです。
とりあえず、クライアントのリトライ周期 (15 秒固定) はダメすぎるので、そこだけは (UNIX 版は .c2bfrc が無いと PROXY 設定が反映されないバグも) 修正してクライアントを公開します。明日には、サーバ側マシンの調達状態とかもう少し具体的なことを公表できると思うので、それまでは手元でのクライアントの起動数を 1 個に制限お願いします。
クライアントソフトウェアを更新しました。目的はエラー時の 15 秒固定リトライという頭を使わないにもほどがある設定を修正するためです。今回クライアントソフトの更新は必須ではないのですが、昨日のような問題が起きにくくなるはずなので、できれば更新しておいてください。
WIN 版には、マシン ID のクリップボードへのコピーメニューも追加しておきました。
現在のサーバスペックについて勘違いしていた。Celeron 1.7G だと思い込んでたけど、旧パーソナルだから Celeron 400M だったんじゃないか。1.7G からの更新なら意味のある選択肢は一つしかなかったから悩みが深かったけど、400M からの更新なら他の選択肢でも意味がある。
今朝のサーバ側プログラム修正でかなり Load Average が下がってくれた(これが昨日間に合っていれば……)ので、どうしようか悩んでいたところだったのだけど、これなら悩むことはない。つーかその場合はどれにするかという別の悩みが出るわけなんだけど。
参考データ。今日の AM 6:00 〜 AM 10:00 までの C2BF クライアントのアクセス数が、6:00〜6:59 で 8192 回。7:00〜7:59 で 8177 回。8:00〜8:59 で 8058 回。9:00〜9:59 で 7991 回。 10:00〜10:59 で 8039 回。MRTG のグラフと比較すると 9 時台と 10 時台にかなり Load Average が下がっているので、今回潰したところはかなりなボトルネックだったと言えそう。
とりあえず新サーバ調達完了まで今日サーバが落ちるか明日落ちるかと心配しながら過ごすという、非常に健康に悪い生活はしなくて済みそう。
寝る前に最後の更新を。サーバが生きている間はクライアントの挙動は今までとなんら変わりません。今日更新したクライアントの挙動が変わるのはサーバが落ちた後だけです。今までのクライアントはサーバが沈むとここぞとばかりに 15 秒間隔でリトライを行い、起き上がろうとするサーバを叩きのめしてくれたのですが、今回更新したクライアントはもう少し穏やかなリトライを行うようになっています。それだけです。
具体的には、15 秒待ってダメなら今度は 30 秒。次は 60 秒。その次は 120 秒と待つ時間を倍々に増やしながら、最大で約一時間待つようなつくりに変更しました。この変更によって、サーバの負荷が限界に達した場合でも運がよければクライアントからの負荷が減ってサーバが自動復帰する可能性が高くなっているのですが、そもそも落ちなければそんな心配はしなくても済むのです。
サーバ側でのプログラム最適化によって、多少(1〜2 割)耐性は上がっているはずですが、それでも現在のクライアント数 (2100) はぎりぎりの場所に近づいていると思います。サーバ置き換えできるのは最良でも 2/14 か 15 になりそうなのでそれまではなるべく控えめにお願いします。
クライアント増加を抑える(サーバの負荷を上げすぎない)為に C2BF クライアントのダウンロードリンクを一時的に削除しました。サーバ置き換え完了後に復活させる予定です。
また、サーバ側の処理に興味のある方向けに、現在のサーバ側ソースを 2/4 版 サーバ側 cgi ソース に置きました。3rd.cgi のソースです。
sakura.ad.jp から新サーバの IP 通知メール到着しました。実質 1 営業日だけでセットアップしてくれたようです。5 営業日はかかってしまう (& 11 日の祝日を挟むのでさらに遅れる) ものと覚悟していただけに非常に嬉しい気分です。
これならば今週末の土日がフルに使えるから、サーバ置き換えの予定をはやめることができそうです。というわけで、P4 2.8G マシンが確保されました。サーバ提供の申し出は感謝だけ受け取っておきます。また、Frozen-Layer の webmaster からのメールは届いています。これから返信を書きます。
しがない客先常駐プログラマとしては、平日の昼間は働いてるフリをしてみせないとサーバ&回線代が稼げなくなってしまうのですよ、悲しいことに。今もまだ H.264 のエンコーダに囚われの身で、動き検索を中心に高速化&高画質化にはまり込んでる日々。C でアルゴリズム実装して、SIMD で高速化を試みて、やっぱり遅いから別アルゴリズムとかやっぱり画質が悪いから別アルゴリズムとか。5 日間周期で繰り返してるときっと嫌になってくると思います。東北大学の同姓同名の方は別人ですので為念。
新サーバの設定を開始しました。判ってはいたことですが、初期状態ではいろいろと入っていないものが多いので設定完了まで時間がかかりそうです。その後に手元の PC を動員して、サーバ側の動作に問題がないか確認する必要もありますし、とりあえず 2/8 24:00 JST (15:00 GMT) の移行を目指して努力しますが、この期日はまだ確定したわけではありません。
移行の手順は以下のように考えています。
DNS キャッシュが残っている間のクライアントでの計算結果が無駄になってしまいますが、一応クライアントプログラムの再起動なしでスムーズな移行ができるようにしたいと考えています。(上記手順に穴を見つけた方はメールください)
もちろん移行作業中にクライアントを停止しておいてもらえれば、移行作業はかなり楽になります。正式な移行日時は明日の 16:00 JST (07:00 GMT) までには決定して、ステータスページで発表します。
移行先サーバの設定は順調に進んでいます。現在 (11:40 JST / 02:40 GMT) 手元の PC をクライアントにしてサーバのテストができる段階まで来ました。このまま特に問題が発生しないようであれば、目標通り、明日の 24:00 JST (13:00 GMT) にサーバ移行ができそうです。
サーバの移行日時を 2/8 日本時間 24:00 に決定しました。以下、移行作業スケジュールです。
参加者へのお願いなのですが、機械が操作可能な場所にないという場合を除いて、最低でも 23:50 〜 00:10 までの間はクライアントを停止しておいてください。停止しなくても計算結果が多少無駄に捨てられるだけになるようにサーバ側を作ったつもりなのですが、不安要素はなるべく減らしておきたいので、お願いします。
誤解している人はいないと思うのですが、日曜から月曜にかけてサーバを置き換える予定です。今夜じゃありません。大丈夫ですよね。移行日時をページに載せてから最低 24 時間は空けないと情報が行きわたらないので、その時間を確保する目的で 2/8 24:00 のサーバ移行を決定しました。まだサーバ側テストが完全に終わっていないからという事情もありますけど。
移行先サーバの設定およびテストはほぼ完了しました。予定通り日本時間で今晩 24:00 (GMT 15:00) に DNS エントリの書き換えを行います。23:50〜24:10 [GMT 14:50-15:10] までの間、操作可能な場所にあるクライアントソフトの停止をお願いします。明日仕事がある方は、寝る前にクライアントを停止させて、明日の朝の起動をお願いします。
今度のサーバではワークデータファイルを MFS (Memory File System / RAM Disk) 上に置いてみました (timecop さんのアイデアです)。シャットダウン時の HDD への退避や、起動時の HDD からの復元も正しく動くように設定できたので利用することにしました。これでかなり負荷を下げることができると思います。
また NT サービス版のクライアントですが、いくつか問題があった (2000 や NT でインストーラが正しく動作しない, 単体版と違う ID になってしまう等) ので、サーバ移行と同時に修正版の ver. 3.1.2 を公開します。
予定通り、昨日 24:00 JST (15:00 GMT) に DNS エントリを書き換えました。旧サーバのアクセスログは 00:10 で停止しているので、想定どおりの移行ができたようです。クライアントを停止して移行に協力してくれた皆様、ありがとうございます。
今日はこの後、01:30 JST (16:30 GMT) まで障害発生に備えて待機して、問題が起きなければ明日の仕事に備えて寝ることにします。後は新サーバマシンで Load Average がどこまで下がってくれるかが気になるところです。
MFS 上に置いてても user.cgi にアクセスが集中すると遅いか (apache の error.log で reached max client を見ることになろうとは)。課題。user.cgi を真面目に書き直す。それでは 01:30 を過ぎたし、新サーバは問題なく稼動しているようなので寝ます。
202.224.183.254 (eaosk2-p253.hi-ho.ne.jp) 様。使用中の PC に妙なものが入っていないか確認をお願いします。この IP からの c2/bf/3rd.cgi への GET_ID リクエストの連発が、サーバへ過剰な負荷をかけているようなので。
アクセスが止まないようだと、hi-ho.ne.jp への相談をしなければならなくなってしまいます。面倒なので本当はそんなことやりたくないのですよ。
申し訳ありません。user.cgi へのアクセス負荷が高いようなので、user.cgi の実行許可を落としました。今日中に書き直して復活させる予定です。
サーバ負荷が高い場合のみ user.cgi の処理を止める形式に修正しました。直近 1 min の load average が 4.0 を越えた場合、user.cgi は停止します。(まだ本質的に直したわけではありません)
以下変更点。user.cgi の処理を止める load average を 2.0 に下げました。ID 無効化する時間を 6 時間に短縮しました。202.224.183.254 からの GET_ID リクエストに対して、"ng - your IP is black listed" を返すようにしました。まだ hi-ho には接触していません。今後の対処はもう少し後で決定します。
jpnic の whois で松下電機産業が出てくるのと IP アドレスの範囲が狭いのは単純に、hi-ho の運営母体が松下なのと、hi-ho がクラス C グローバルアドレスを複数取得する形で IP アドレスを確保したからだと推測してます。中からのアクセスなら 宝石名.mei.co.jp での PROXY 経由アクセスになるはずですし。
社員が社内斡旋で hi-ho と契約してるという可能性も捨てがたいですけど、流石に PROXY すら通さずにこんなバカなことやる人はいないでしょうし……。とりあえず偶然踏み台に使われたかわいそうな PC だと解釈しています。その割には初回停止した時のタイミングが良すぎた気もしますが。
時々 HTTP が限界に達する現象が出ていましたが、その原因が判明しました。原因の半分は user.cgi に、もう半分は MFS 上から hdd にデータをバックアップするプログラムにありました。内容は複数の資源を互いにロックしあう形式のクロスロックによるデッドロックです。バックアッププログラム側を 19:30 に修正したので、以後固まることはなくなると思います。
hi-ho からの GET_ID は送信元 IP が変わってまだ続いていますが、取得された分の ID はほぼパージが終了したので、パフォーマンスに与える影響は微々たるものになっています。ID 無効化の期限も 24 時間に戻しました。
[Q1] log.txt に "[E] failed on get_id() - XX wait YY sec" と延々と (XX と YY の部分が増えながら) 表示される。
[A1a] http://www.marumo.ne.jp がブラウザから見えるかどうか確認して、見えない場合は見えるように調整してください。
[A1b] http://www.marumo.ne.jp がブラウザから見えるけれどもこのエラーが出る場合、ZoneAlarm 等の個人用 FireWall ソフトで C2BF クライアントのネットワーク接続が遮断されているか、C2BF で PROXY の設定がされていないかのどちらかの可能性があります。FireWall ソフトを使用している場合は、C2BF クライアントのネットワークへの接続を許可してください。ブラウザに PROXY の設定がされている場合は、C2BF クライアントでも同じ設定を行ってください。
[Q2] log.txt に "[E] failed on get_id()" とだけ表示されて停止してしまう。
[A2] ひたすら GET_ID リクエストを投げ続けるクライアントを作成した方が居たため、一部の IP アドレスからの ID 取得要求は拒絶するように設定しています。この問題が出た場合は、kazhiro@marumo.ne.jp まで大体のアクセス時刻と可能ならば IP アドレスを連絡してください。
[Q3] log.txt に "body[0] = ng - your ID is not exist on the server" "[E] failed on get_block()" と表示されて停止してしまう。
[A3] ID 取得から 24 時間が経過してもブロック報告数が 0 のままのクライアント ID はサーバ側で削除するようにしています。このため、一度 C2BF クライアントを起動したことがあるけれども、すぐに止めてしまって一日以上経過している PC では、このエラーが出ることがあります。この場合レジストリの "HKEY_CURRENT_USER\Software\marumo\c2bf.exe" を消去してレジストリ上に残っている ID を削除してから C2BF クライアントを起動してください。
[Q4] log.txt に "body[0] = ng - reported 'key/code' pairs are missmatched. please contact admin and report your environment detail." "[E] failed on report()" と表示されて停止してしまう。
[A4] サーバ側でブロックを割り当てる際に計算した鍵と暗号文が、クライアントから報告された鍵と暗号文に一致しなかった場合にこのエラーが表示されます。もしオーバークロック等をしているようであれば止めてください。正しい鍵が存在するブロックが割り当てられているのに、発見できなかったと報告する危険性があります。オーバークロックなしでこのエラーが出た場合、使用中のクライアントのバージョンや、実行環境などを報告してください。
更新が無かった理由は体調不良で寝込んでいたためです。胃腸が弱っているのか、まともな物が食べられなかったので快復に時間がかかってしまいました。今日は熱が下がっていたのでもう大丈夫なはずです。
marumo.ne.jp のドメイン更新料を振り込み。早いこと DNS とメールサーバ機能も新サーバに移転して旧サーバの解約手続きを進めなければ。後は移行の都合で停止してしまったバグ報告ボードの復活もさせなきゃいけない。
旧サーバを本格的に解約するべく、DNS & SMTP 機能の移行を進めようと作業したのだけれども……。属性型ドメインの NE.JP もいつの間にか登録事業者経由じゃなければ登録内容の変更ができなくなっていたのね。昔は直接 JPNIC にメールを出せば済んだのに。
sakura.ad.jp のページを確認した限りでは無料でやってくれるみたいだからいいのだけど、多分月曜にならないとメール出しても無駄だろうなー。後はログの吸出しと /home & /var 以下の削除を済ませて、19 日までに解約のメールを出せるようにしとかなきゃ。(一応翌月末までは使えるはずだけど)
128 EB (エクサバイト)。単純に選択暗号文と全鍵での対応平文の表を作った場合、これだけの記憶容量が必要になる。今後数ヶ月間でこれだけのデータを記録できるストレージは出現しそうに無いので、Time/Memory Trade Off ではそれなりのイカサマが必要になる。そんなこんなで key[n] = c2_dec(code, key[n-1]) & 0x00ffffffffffffff の挙動調査とかを開始していたり。
とりあえず C の標準 rand() で key[0] を作って、code は 0xffffffffffffffff に固定して 10000 回まわしてみたのだけれども、MSB 28 bit 全部が 0 になる前にループに落ちてしまうのが約 40%。成功率を上げようと思ったらやっぱりループに落ちるケースも拾っておかないとまずいんだろうな。
後は rand() があんまりランダムじゃない (key[0] に偏りが出てる) ので、ここも何とかしなければいけない。流石に 10000 回程度では重複鍵は出ていないみたいだけれども……やっぱり 16 bit 乱数を組み合わせてランダムな 56 bit 鍵を手に入れようってのは虫がよすぎるか。ハッシュ関数とか MD5 の利用も考慮することにしよう。
引き続き Time/Memory Trade Off の実現方法考慮のための実験中。とりあえず key[0] の作成に rand() を止めて複数の方から推奨された メルセンヌツイスター を採用してみる。
とりあえず 4000 個の key[0] で前回同様 key[n] = c2_dec(code, key[n-1]) をまわしてみるものの、MSB 28 bit が all 0 を持たないループに落ちるケースが 4 割前後。ループ検出か MSB 28 bit が all 0 になるまでに必要な平均回数は 0x06000000 回。MSB 28 bit all 0 が成立した最終鍵でユニークなものは 4% 程度 (全試行に対するパーセンテージでは 2.5%)。
64 bit の平文出力から MSB 8 bit を削ることで次の 56 bit 鍵を作り出しているので、この結果で妥当なのかもしれないのけれども……最終鍵一つ当たりのデータ量が増えるのは困るなー。今のサーバマシンだと 40 G しかテーブル用には使えないからデータがあふれてしまう。かといって同じ乱数列かどうかをサーバ側で検証するのは無理っぽいし。重複鍵を保持できるのは精々 10 パターン程度なんだがどうするべきか。
昨日に引き続き、さらに 6000 個(あわせて 10000)の key[0] で回してみるものの、ユニークな最終鍵は 60 個しか増加せず。おそらくこのまま回数を増やしていっても対数的にしか増加していってくれないだろう。
とりあえず今まではシードが 1 つで MT を使って 10000 個 key[0] 作成という形にしていたけれども、開始鍵のバリエーションを増やすために一つのシードから作る開始鍵を 100 個に制限してみて放置中。なんとなく結果は変わらないような予感はあるので、覚悟だけはしておこう。
MSB 28 bit が特定値になったものを記録するよりも、loop の検出を終了条件にした方が良いのかもしれないと妄想中。今日帰ったらその方針でテストプログラム書き直して回してみることにしよう。
えーとここ3回ほどの記述内容がわからない方へ。この辺 から MARTIN E. HELLMAN "A Cryptanalytic Time-Memory Trade-Off" を読む (DjVu 版なら誰でも読めます) とひょっとしたら何を言っているか判るかもしれません。上記 URL で AUTHOR index から 1st letter 'H', 2nd letter 'e' でたどり着けます。
後は横浜国立大の松本勉先生の DES への適用例 が有名だったりするのですが(悲しいかな IPSJ のメンバーではないので論文は読めない)……あちらはテーブルに 512G 使って成功率 80% なんですよね。テーブルサイズ 32G で同じ 56 bit 暗号に挑むのはちと無謀かもと後悔してるところだったり。せめて 256G あれば成功率 40 % までもっていけるかなー。
key[n] = c2_dec(code, key[n-1]) のループ検出自体は、key[n] に対して MSB から 0 bit の数 (number of leading zero : nlz) を数えておいて、nlz = 0〜56 のそれぞれの場合での最小値を記録しておき、同じ鍵値が出てきた時点でループとして判定という実装で一応正しく動いている模様。この判定方法だと key[n] の挙動次第ではループ判定をすり抜ける可能性もあるのだけど、今のところそれは出ていないようなので本番でも試行回数にリミットを設けておけば大丈夫だろう。
key[0] から開始してループを検出した時点での key[n] の n の値は 1500 回の試行で平均 200M。上の式によって作成される乱数列が 2^56 の鍵空間内で完全に重複がなければ 320M エントリーで全鍵を格納可能なテーブルが出来上がるのだけれども……実際には 64 bit から 56 bit への縮退があるから乱数列の合流があり、何らかの重複は絶対に発生する。問題は、重複率が最終的にどの程度になるのかの見積もりができていないことと、同じ乱数かどうかの判定をどうするかというところ。
テーブルのサイズを節約するために、完全に同じ乱数列であるのならばより長いものだけを記録しておいて、短いものは破棄したいのだけれども、同一の乱数であるかどうかの判定方法が思いつかない。
例えば上の画像のように、最終的に同じループに落ちる乱数開始点 A, B, C がある場合、A さえ記録しておけば B を記録する必要はないけれども、C は記録しておかなければいけない。何も考えずに全部記録しておくのが多分最強なのだけれども、それには 40G 程度では全然足りなくなってしまう。むー土日にもう少し考えてみることにしよう。
鍵が見つかれば C2BF は止まります。鍵が見つかった後の GET_BLOCK 要求には、もう鍵見つけたら働かなくていいよとサーバ側が応答を返すようになってますので。
log.txt に見つかった鍵を出力して、GUI 版ならば tips の文字列も見つかった鍵に書き換えて、サービス版ならば働かなくなり、UNIX 版ならば終了します。
code の全ビットが立っている場合、key[n] = c2_dec(code, key[n-1]) は最終的にループに落ちてくれるようなので、ループ内での最小値となる key でループを識別して、ループとの合流ポイントで乱数列を区別しようという方針で土日にいろいろと試してみたのだけど。
合流ポイントの取得がまだ正しく動いていない。流石に富豪的プログラミングでは正しく動作させることができているのだけれどもメモリ使用量を削減しようとしてバグの巣に突入してしまった。多分もう少し調べればバグを潰せると思う。
"Fate/stay night" 読了。2/14 〜 2/22 にかけて 50 時間ほど消費してエンディング5種およびタイガースタンプ40個コンプリート。評価 75 点。すごい疲れた。まだ目が痛い。
むー 70% を越えようとしているのにまだ鍵が見つからないとなるとかなり不安になってくるな。まだエラーチェック導入前に調べた領域という逃げ道があるとは言えども……。来週になってもまだ見つかって無いようだと、その先はすごく健康に悪い日々になりそう。
Time/Memory Trade Off のテーブルサイズ縮小を引き続き検討中。ループとの合流点は一応正しく取得できるようになった。昨日一晩流してみたところ、691 個の開始鍵でループ内の最小鍵とループとの合流点取得ができていた。もう2・3日動かしてサンプルを増やす必要があるけれども、とりあえず現状での分析。
ユニークな最終ループは 5 個で、ユニークなループとの合流点は 40 個。とりあえず適当に選択した合流点に到達する開始鍵 72 個で同じ乱数列に含まれるものがないか調べてみたのだけれども……。これは現実的ではないということが判った。全組み合わせ 2628 通りでチェックするのに 3 時間消費して完全重複なしと判明。クライアント側に割り振るにしても負荷が高すぎる。鍵が増えるにしたがって O(n^2) な時点で論外。
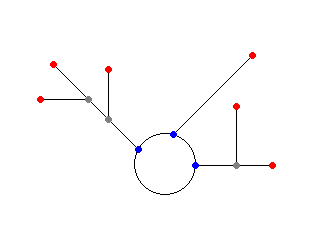
クライアント単独で求めることができるのは上の画像での赤丸(開始鍵)と青丸(合流点)をおいた部分(とループ内での最小値)なわけで、同じ合流点に到達する開始鍵があるようなら、その二つの開始鍵同士での合流点(灰丸部分)を求めて、サーバ側ではノード間の接続関係と距離だけを記録するようにしようかと妄想中。
問題は果たしてそれでテーブルサイズの縮小ができるかどうかなのだけれども……なんとなく単純に開始鍵と合流点と距離だけを記録しておく方がテーブルサイズが小さくなるような気が。ノードの接続関係を記録する形なら、乱数列の包含関係を調査して大きなものだけを記録ということもできるけれども、そもそも完全に包含される乱数列というのはどの程度の割合で出現してしまうのだろう。(多分 Time/Memory Trade Off での鍵発見成功率と等しくなるはず)
単純に開始点と合流点を記録する形だとテーブルサイズ 40G でも 2G エントリーは保存できる訳なのだけど、それで成功率 46% が (CBC の 2nd ブロック以降をターゲットにしているので、連続して成功しなければブロック鍵は判らないため、自乗しても 20% を確保できる 46% を目標にしている) 確保できるなら何も考える必要はないのかも。
PowerPC なら AltiVec 使って書き直せばものすごく速くなるのだろうけど……。実物持ってないからテストできないしそもそも x86 以外のアセンブラ書いたこともないし。
現在状況の文字表示欄をすこし下にずらしました。つまりそういうことです。100% 調べても鍵が見つかっていない場合、それぐらいの領域を調べなおすということです。
具体的には 0x000000〜0x11d7f2 の領域 (約 7%) を調べなおすことになります。これでも見つからない場合は、完全に敗北宣言をすることになります。
鍵が見つかってくれることを祈りつつ、敗北宣言の文面を考えてたりするあたりに駄目人間の自覚を感じてしまったりして悲しいですね。