たびたび書いているように、私は SSE2 が嫌いだったわけなのだけど、ここ 1 週間ほどでさらに SSE2 が嫌いになってしまった。
どうやら Pentium M でも SSE2 の 128 bit 整数命令が使えるらしいということに気が付いて、某最適化フェーズで追い詰められているお仕事用に SSE2 コードを書いたりしていたわけなのだけど。どこをどう書いても Pentium M では SSE2 が SSE よりも遅くなってしまう。
私の書いてるコードがまずいのかもしれない。確かにそれはある。依存関係 (Dependency Chain) の引き伸ばしとループアンロールぐらいしかやっていないから、確かにあまりいいコードではないのだろう。
でもさ、どうして Intel が配布してる AP-945 の IDCT コードをそのまんまで 8M 回動かしてみるだけのものでも SSE2 の方が SSE より遅くなるの? どー考えても Pentium M では SSE2 の 128 bit 整数命令は SSE/MMX の 64 bit 整数命令よりも遅いとしか考えられないんだけど。
以下、AP-945 のコードで SSE2 vs SSE を比較するだけのベンチマークを動かした時の結果。Pentium M は Banias コアの 1.1GHz モデルで Pentium 4 は Presscot コアの 3.6GHz (560)。
| Pentium M | Pentium 4 | |
| SSE | 2.974 sec | 1.375 sec |
| SSE2 | 3.315 sec | 1.063 sec |
なまじ Pentium 4 では速く (短い時間しか必要としなく) なったりしてる辺りが憎らしい。つーか遅くなるぐらいなら Disable にしておけ。そうすればそもそも SSE2 使ってみようなんて考えはしなかったのに。
まあ SSE2 の仕様自体が政治的・営業戦略的に追加されたものっぽい(とても技術的最善を追求したものとは思えない)から、そもそもこーゆー結果も当然なのかもしれない。
主に SSE2 の 128 bit 整数 SIMD 命令に関して。SSE2 の整数 SIMD 命令は、MMX/SSE で追加された整数 SIMD 命令に対する、レジスタ幅の拡張という形となっている。今までは浮動小数点 SIMD 命令でしか利用できなかった 128 bit SSE レジスタが、整数 SIMD 命令に解放され、MMX/SSE での 64 bit 整数 SIMD 命令が SSE2 では 128 bit 整数 SIMD 命令として利用できるようになっている。
同じ量のデータを処理する必要がある場合、128 bit 整数 SIMD 命令は 64 bit 整数 SIMD 命令の半分の命令数しか必要としない。仮に 64 bit 整数 SIMD 命令 (MMX/SSE) と同じ速さで 128 bit 整数 SIMD 命令 (SSE2) が動くならば、128 bit 整数 SIMD 命令では 1/2 の時間で同じ結果を得ることができるはずとなる。ところが、実際には Pentium 4 でも 7/10 程度の時間にしかならないし、Pentium M に到っては処理時間が増えてくれる。
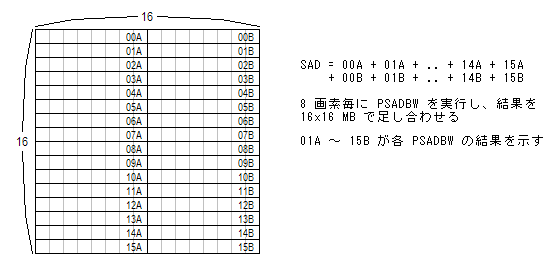
ここで、PSADBW という整数 SIMD 命令に登場してもらう。これは SSE2 の実装の最暗部を露出してくれている命令なので。64 bit 整数 SIMD 命令での PSADBW は、8 個の BYTE (8 bit データ) の SAD (Sum of Absolute Difference : 差分絶対和) を取り、結果を最下位 WORD (16 bit データ) に格納してくれる命令だった。実際に MPEG エンコーダで使われる場合、次の図に示すような処理で利用される。
同じ PSADBW 命令が 128 bit 整数 SIMD となった場合、普通の人は次の図に示すような処理で実現できるようになるだろうと期待するだろう。
![SSE2 128 bit Integer SIMD - 16x16 MB SAD calculation [ideal]](junk/img/psadbw_128bit_ideal.png)
しかし、実際の 128 bit 整数 SIMD 命令の仕様は異なる。何故か (てーか理由は明らかに推測できるのだが) 64 bit 整数 SIMD と大差ない、次の図に示す形でしか利用できない仕様となっている。
![SSE2 128 bit Integer SIMD - 16x16 MB SAD calculation [real]](junk/img/psadbw_128bit_real.png)
128 bit 整数 SIMD 命令での PSADBW では、先頭 64 bit 分の SAD と、後半 64 bit 分の SAD を別々に返すため、このような非効率的な利用法しか取れなくなっている。これを見た 100 人中 80 人以上が「SSE2 って、MMX 実行ユニットを自動的に 2 回呼び出すだけなんじゃないの?」という推測をするだろう。私も当然そのように考えた。おそらくこの推測は正しい。
Pentium 4 での SSE2 命令に必要なレイテンシとスループット [結果を受け取れるまでに必要なクロック数] のデータもこの推測を裏付けてくれる。整数 SSE2 命令では、MMX 命令の 2 倍のレイテンシとスループットが必要だと、「Intel アーキテクチャ最適化リファレンスマニュアル」には記載されている。
何よりも怒りを呼び起こすのは、この PSADBW の仕様自体が「将来に渡っても本物の 128 bit 整数 SIMD 実行ユニットなんて用意しませんよ」と主張しているところだ。当座は MMX 実行ユニットを 2 回呼び出す形で 128 bit 整数 SIMD 命令を実装するにしろ、将来 128 bit 整数 SIMD ユニットを用意して意味を持つような自然な PSADBW の仕様にする訳にはいかなかったのだろうか。
ついカッとなって、次のようなものを作ってみたくなったりもしたのだけど、人間性を疑われそうなので寸前で思いとどまった。
【名称】 HT 対応 AviUtl プラグイン 【機能】 HT 対応 CPU で、エンコード中の CPU 負荷が 100% に到達するようにします 【詳細】 ソースを読みましょう
実装は誰もが思いつく通りで、以下のようなコード。
static int __stdcall as_technology(void *p)
{
int as;
FILTER *fp = (FILTER *)p;
while(fp->ex_data_size){
as += 1;
as -= 1;
}
return 0;
}
BOOL func_save_start( FILTER *fp, FILTER_PROC_INOF *fpip )
{
LONG trash;
fp->ex_data_size = 1;
fp->ex_data_ptr = (void *)__beginthreadex(NULL, 0, as_technology, fp, 0, &trash);
return TRUE;
}
BOOL func_save_end(void *fp, void *editp)
{
fp->ex_data_size = 0;
WaitForSingleObject((HANDLE)fp->ex_data_ptr);
CloseHandle((HANDLE)fp->ex_data_ptr);
return TRUE;
}
かなり心が病んでいるようだ。
仕事も InterBEE 前の目標自体は達成できて、「ひぐらし」も一通り読み終わったので懸案事項の作業へ復帰。一通り SSE2 をこきおろして、AS テクノロジによる HT 対応を妄想したらすっきりしたし。とりあえずコマンドラインで AVI1.0 の ReMuxer を作る辺りから。
とりあえずインタリーブを考慮しない muxer は出来上がっているのだが、普通に使う場合、インタリーブ周りの作業は muxer 内で閉じてた方が良いだろうということで、muxer 内部でバッファリングする方向で作り直し中。
むー旧バージョンとの違いが大きくなるけど……まあこのほうがインタフェースの切り方としては自然に (シンプルで依存関係が少なく) なるから、問題ないと思うことにしよう。後は適当なサンプリングレートコンバータも追加して ACM の問題で動かないとかが少なくなるようにしとかなきゃなー。
OK。muxer はほぼ完了。後はサンプル周波数変換を何とかしてからプラグインインタフェースに整えてあげるだけだな。
一つインタフェースを作っては「美しくないー」と叫んで消して、もう一つインタフェースを作っては「実行効率が悪いー」と叫んで投げ出す日々。これを評価するとしたら無駄なこだわりとしか言いようがないのが悲しいところ。
てなわけで、PCM フォーマット変換にずっぽりとはまりこんでしまい、まだ完成の目処が立っていなかったり。あー ACM のフォーマット変換の音質がまともで、12kHz とか 16kHz もサポートしてくれていればこんなものを作らずに済むのだが。
仕事で 1 回作ったことがあるものだけに、インタフェースさえ綺麗に固まれば実装はそんなに大変じゃないと判ってはいるのだけど……。実装に移れるまではもう少しかかりそうだなー。
充実した毎日。何かが大いに間違っているような気もするけれども。とりあえず薔薇乙女に関しては Amazon で DVD 2 巻まで「ポチッとな」済み。
実家の光環境も 13 日に工事が終わり、借りてる部屋からの VNC がたいへん快適になった。光(TEPCO) - 光(NTT-VDSL) なので当然といえば当然なのだが。
ただ、このために通信費が月 \30k に到達してしまったのが……はてさて、どこから削るべきだろうか。やっぱり現在 DION 経由で利用している B flets と AirH" を SRS さくら でまとめるあたりからかなぁ。メールと Web ページはなくなるけど、安くて固定 IP らしいし。
発動中。9 月半ばから 10 月までの狂ったような働き方の埋め合わせをするべく、18:30 頃に職場を出るぬるま湯生活を実行中。人生にはメリハリってものが大事だよね。
InterBEE に連行されて三日間説明要員としてブース張り付きな人には同情するけど、正直な気持ち自分でなくて良かったと安心していたり。「出展してるのはアプリケーションで、エンコーダじゃありませんから」と言ってしまえる幸運をかみ締める。
むー帰宅後にコードを書く気力が起きないのはなんでだろう。折角時間はあるのだからこの間に作業を進めて週末リリースを目指すつもりだったのに。
このニュースを見た瞬間は、おいおい、コピー機まで著作権法違反扱いかよ [注: 同一性保持権を持ち出すまでもなく、図書館においてあるコピー機以外で著作物をコピーすることは著作権法違反です。著作権法 30 条 1 項において、公衆が利用可能な自動複製機械による私的複製は侵害扱いにされていますから。コンビニでコピー機の使い方を聞かれたら、「ソースは何ですか・著作物をコピーすることは著作権法違反なのですが知っていますか・もしも著作権法違反がなされるのであればこのお店に迷惑がかかるのです」というような脊髄反射著作権厨的態度を取ることを推奨します] と考えたのだけど、パテントサロン 経由で 民放連会長 定例記者会見概要 [(社) 日本民間放送連盟] に到達。
どうやらこの発言の趣旨は、放送の録画時に、録画機器によって自動的に CM カットがなされるようであれば対抗処置が必要になるので、検討する必要がある程度だったらしい。以下引用。
放送局は、放送番組の著作権と著作隣接権を有しており、放送されたものと、録画されたものが同一であることを求めたい。したがって、録画する際に、機械がCMを自動的に飛ばし、放送内容と変えてしまうことは、いかがなものかという意見もある。いずれにせよ委員会で検討し議論を深めたい。
ごくごく普通の意見のような気がするなぁ。むしろこの発言から「CM カットは著作権法違反」という見出しを考案できた記者のほうが電波が入っているような。
安めの物も Amazon アソシエイト 経由で買うようにして、パフォーマンスプランの紹介料率を上げてみるテスト。と言っても、精々 20 を超えて 0.5% 上積みされるかされないか程度なのでリターンは少ないのだけど。
そんなこんなで Dimitri From Paris "Neko Mimi Mode" (2004, ビクターエンタティメント) が到着し、仕事中にループ再生してたりするダメ人間。
現在のやる気のない状況にぴったりな曲 & 歌詞で素晴らしい。流石に 4 連休が明けたらこんな生活は無理だろうから今のうちに精一杯怠けておかないと。
一人暮らしの雇われ PG としては、Amazon が配送時間帯指定に対応してくれると大変嬉しかったりするのだが……いい加減ペリカンの配送センターに再配達依頼の電話を掛けるのが面倒になってるんだよなー。
うーむ海外相場で順調にドルが下がっているなぁ。そろそろ \103 を切りそうだ。\100 を切ったら VTune を買おうかと思っているのでもうしばらく注視しておくことにしよう。
みみっちさに悲しくなったりもするけど、$699 の品なので、\105 と \100 では \3500 違ってくるとなると馬鹿にはできなかったり。
客に買わせるという手はあるし、頼めば確実に買ってくれるはずなんだけど、手続きが面倒なのと自由にインストールできないのは不便なので。自前でライセンスを確保しておこうかと。
メイッぱい ANR (Active Noise Reduction) 向きで、作るのもそんなに大変ではなさそうな気がするのだけど、やる気がでない。
なにしろサンプルがないしなぁ。後、インタレース解除前の 13.5MHz でキャプチャ直後の絵にしか使えないから運用が大変になるという問題もあるし。妄想段階で止めておこう。
ついうっかり作りたくなってしまった人への技術的情報。素直なビートノイズ (輝度にだけ乗っていて、波形は正弦波) なら、逆位相のノイズ波形を輝度に加算してやれば綺麗にノイズだけ消えてくれるよねという話。
ソースが BT.601 系の 13.5MHz キャプチャなら無効領域のサイズもすんなり判るはずなので、その分を考慮してやればそれなりな結果にはなるはず〜。ノイズの周波数や位相に関しては単色領域で FFT 使えば検出……できる……はず。多分。
後ろ向きな方針で「拡張 AVI 出力」の面倒を見ていたり。とりあえず削除される予定の機能は以下のとおり。
でもって、次回のリリースでは追加されない機能は以下のとおり。
追加されるのはこれだけ。
なんだか消えた機能の方が追加される機能よりも多いような気がするけれども気にしてはいけない。さーて今日中にテストまで到達できるかなー。
間に合ってないし。VCM 制御部分の見直しにまで手を出してしまったため、プラグインの形でリンクを通すところまで、昨日のうちにはたどり着けず。帰宅後に頑張ろう。
何とか出力テストに移れる状態まで進み、とりあえず出力 AVI ファイルを見る限りでは問題なく動いてるように思える状態まで到達。残りは設定用ダイアログの修正のみ。何とか今週中には公開できるところまでたどり着けそう。
むー途中仕事でくたばったり「ひぐらし」ったりしてたとはいえ、時間がかかりすぎだなぁ。何とかしたいところだ。
公開。変更点は音声対応。
0.1.x 系列までとはだいぶソースの構成を変えてしまったので、VFR 対応改造にはそれなりに作業が必要になります。VCM/ACM/MUX で別ソースに分けて、NULL 水増しは VCM 内で行っているので、基本的には vcm.h/c と exavi.c を突付きまわすだけで済むはずなのですが……。
とりあえずテストとデバッグに疲れたので寝ます。一応 XviD (B フレーム OFF) および WMV 9 VCM (日本語版) と MP3 では正しく動きそうなことは確認しましたが……何かエラーが表示された場合は……なるべく詳しい情報をお願いします。
起きた。今後の予定は非圧縮フレーム対応・XviD B 対応・YUY2 対応等、VCM 周りの拡張を行って、その辺がおわったら AVI 2.0 対応検討の予定。ただ、(音声対応だけは)きっちり終わらせる と書いてから、実際にリリースできるまでの期間が 1 年半以上だからなぁ。
今回はそんなに時間をかけたくないなー。出来るかどうかは別として。
YUY2 対応および非圧縮対応は意外と簡単に完了。一応 XviD の B VOP 対応が完了した時点で 0.2.1 として公開予定。
さて XviD をソースからビルドして、以前 購入した MPEG-4 Visual の仕様書を元に VOP タイプ判定用コードを書いてと。エンコード時の振る舞いとデコード時の振る舞いが判れば何とかなるだろうとは思うのだが……。
再生時に NULL フレーム処理と B での表示タイミングのズレがどうなるかが微妙だからなぁ。後はキーフレームの強制 I 圧縮とか。今は一応フラグを設定しているけど無視されてるはずだし。
AviUtl が標準で VFR 対応してくれるのが一番なのだけど、func_get_flag() で 24fps 周期とか 30fps とかが取れるだけでもだいぶプラグインを作るのが楽になるのじゃないかなーとか妄想してみたり。8 fps 対応とかはコピーフレームフラグで何とかなりそうな気がするのだが。
ナニがアレって出力プラグイン側では間引き後の、0 原点の連続値でしかフレームインデックスが取得できないし、フィルタプラグイン側では選択開始範囲と選択終了範囲と、後は個別に func_is_saveframe() で地道に調べるしかないし。
VFR 作ろうとしたけど、インタレース解除プラグイン作ろうとしただけで力尽きた人間なので見当違いの事を言っている可能性もあるんだが、実際に作った人とかはどんな風に考えてるのかなーとか気になったり。いや、そもそも AviUtl が今後更新されることがあるのかというのも不安点なのだが。
DivX/XviD の VfW 経由 B VOP 対応に関しては大体理解した。以下、エンコード時の挙動 (packed bitstream での)
![DivX/XviD How to support B picture [encode phase]](junk/img/vfw_mpeg4_b_enc_packed.png)
この図はアプリケーション側から CODEC にフレームを渡したときに、どうなるかをメモしたもの。矢印の向きがデータの移動方向。CODEC からの出力は I[X] / P[X] / B[X] というものと、0x7F / P(NC) てのがある。
このうち、I[X] / P[X] / B[X] が普通の MPEG-4 のピクチャで、0x7F は B フレーム用のラグを記録するためのダミーデータ [AVI に記録してはいけない] で、P(NC) は、Not Coded かつ modulo_time_base_count=0, vop_time_increment=0 なダミーデータ。P+B の形式で渡した二つのピクチャのうちの P 側を表示させるタイミングをデコーダに通知するためのダミーフレーム [AVI に記録しなければいけない]。
packed bitstream のチェックを外した場合は P+B という形式のデータがなくなり、同時に P(NC) も発生しなくなる。
というわけで大体の仕組みは理解し、やっぱり邪悪だよなぁという思いを深くする。NULL フレーム水増し 120 fps も邪悪度では似たり寄ったりなわけだけど。
基本的に今まで出現した 0x7f の数だけのディレイが付いたデータを出力していると処理すればよさそうなのだけど、例えば上の図の Frame[4] を NULL として扱いたい場合、Frame[3] の後に追加すべき NULL フレームの数が増えるわけなんだが、Frame[3] 相当のデータがデコードされるのは、Frame[5] を CODEC に突っ込んだ後に出てくるデータな訳で……むきぃ。
後は CODEC 内部のバッファに溜まっているデータをフラッシュさせる方法さえ判ればとりあえず (強制キーフレーム挿入以外の) 対応はできそうなのだが……やっぱり終端フレームを何度も突っ込んで P で正しく終わるようにするしかないのかなぁ。