{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
新年早々生臭い話。昨年末に口座開設を行い、株取引を開始した。証券会社は Me ネット証券。約定手数料はそれなり (700〜2000 程度) にかかるけれども、野村證券等の大手と比較すれば安いほうだし、三菱東京系ということでの安心感とかをそれなりに考慮して。
複数気配値 (指値注文状況) をリアルタイムで見ることもできるし、スクリーニングツールも充実してるので使い始めてから1週間での感想はとりあえず満足というところ。QUICK や QuantsReserch の提供情報との間での連携が悪いところが不満点。
引きこもりデイトレーダーになるつもりは無いので、基本的には流動性が高くて、値動きが少なく、配当利息が高めの割安株を購入していく予定。今は年始休みの期間を利用しての銘柄物色中なのだけど……ソトーの中間配当 200 円とかいう美味しい話はそうそうころがってないのだろうなぁ。
怠けている。サラ・ウォーターズ「荊の城」(2004, 創元推理文庫) を読みながら。年末からぼちぼちと読みはじめて、今は上巻を読みおわったところ。
普通ならもうすこしはやく読めるものなのだけど、何となく気が乗らないせいか進むのが遅い。10 ページぐらい読んでは止めてとかいうのを繰り返してる。
拡張 AVI 出力のバグ報告は、どうやら旧バージョンの設定情報が更新されない状態で発生する問題らしいと理解したのだけど、対策方法をどうしたものかと悩んでいる。
いまだに手元の環境では再現できていないので、いまひとつ対策に自信がもてなかったり。何とか発生状況を再現できないか、もう少し調べてみるつもりなんだけど。
まだ怠けている。「荊の城」は読了。ヒロイン二人が「チカネちゃん」だの「姫子」だの言い始めそうな気がして困ったりもしたが、第二部から先はすんなりと読めた。「神無月の巫女」 19 世紀ロンドン編としてしか見ようとしない間違った読みかたではあったが。どうやら脳にかなりの毒が回っているらしい。
拡張 AVI 出力のバグレポートの件。提供してもらったファイルと同様のものを作ることができた。ただ、かえって対応に困ってしまう結果となっていたりする。
とりあえず、CODEC に対して YUY2 だと通知しながら RGB24 のデータを渡すようにプログラムを改造したところ、提供してもらったファイルと同様のものが出力された。しかしコードを見る限りでは、func_get_video_ex() に渡す format 引数は、CODEC に渡す FOURCC と同じ変数を使っている訳で、aviutl 本体がプラグイン側から YUY2 フォーマットを要求されているにも関わらず、RGB データを渡すことがあるという結論に到達してしまう。
無理をすればチェック用のルーチンを入れることもできそうだけれども、非常に遅くなってしまう。その手の問題が発生した場合、ini/cfg/sav ファイルを消して作り直してみてくださいと個別対応するしかなさそう。
MPEG-2 VIDEO VFAPI Plug-In の更新は、0.6.50 で入れてしまったバグの修正。PCM バッファをモノラル対応に書き換える際に、変更ミスを入れてしまっていた。テストさえしていれば気づけたバグなので完全に知性の欠如。
さらに怠けている。年末に買った本も読みおわり、やることもなくなってしまったので株価情報を見ることしかしていない。かなりダメな時間の使い方のような気がする。
いい加減相場を眺めるだけの生活もアレだと考えたので、スカイマークエアラインズ [9204 : 東証マザーズ] を気配値を頼りに 209,000 で 1 株買ってみた。当初の高配当利回りで値動きの少ない安定株をという方針はどこにいってしまったのだろう。
12/17 に発表された、3/31 に 1:200 での株式分割を受けて、年末にストップ高を 2 回繰り返したあと上昇傾向に乗っている銘柄。昨日の大発会でも、ストップ高近くまで上がっていたし、減損会計と減資の発表も織り込み済みで ROE と PBR を見ても 300,000 までは上昇が続くだろうと踏んだのだけど、そんなに外した予想ではなかったらしい。11:00 の前引けには 241,000 の値をつけてくれた。
ここで 14:55 頃に売り注文を入れればデイトレーダー見習い Lv.1 のスキルを手に入れるのかもしれないけど、一応分割権利確定までは保有してみる予定。どうかライブドア [4753 : 東証マザーズ] のように分割後 2 ヶ月で半値以下なんてことは発生しませんようにと祈りつつ。
メールが入っていたので、VC.NET 系での AviUtl 用プラグインのプロジェクト作成方法を。プラグインなら何でも良かったのだけど、とりあえずアセンブラを使っていない比較的素直なもののなかから、一番最後に手を入れたものをサンプルに。
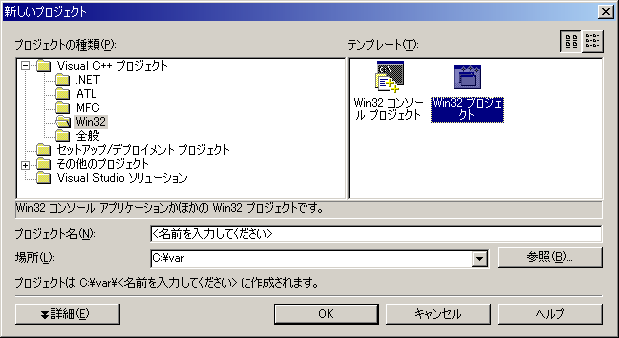
まず、プロジェクトの新規作成を、「ファイル(F) -> 新規作成(N) -> プロジェクト(P)」から実行。次のダイアログで、「Visual C++ プロジェクト -> Win32」から「Win32プロジェクト」を選び、適当なプロジェクト名をつけて「OK」を。 [画像]
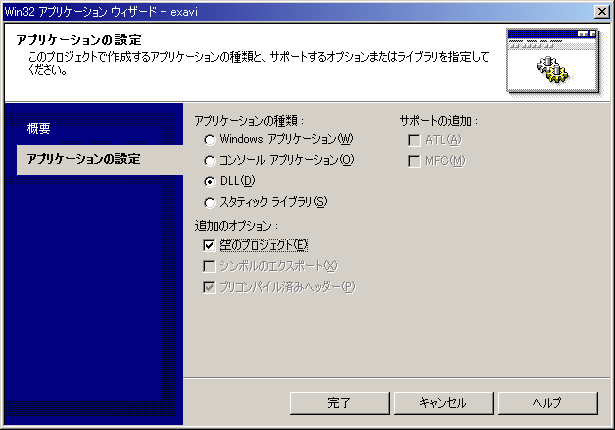
すると、次のダイアログが開くので、「アプリケーションの設定」から「DLL」と「空のプロジェクト」にチェックを追加して完了する。[画像]
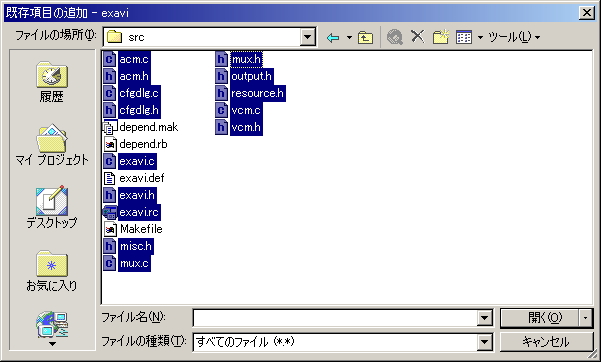
これでとりあえずプロジェクトが用意できたので、既存のソースファイルを追加する。「ソリューションエクスプローラ」からプロジェクトを右クリックして、「追加 -> 既存項目の追加」を選ぶ。出てきたファイル選択ダイアログボックスでは、*.c と *.h と *.rc のファイルを全て選択して開く。[画像]
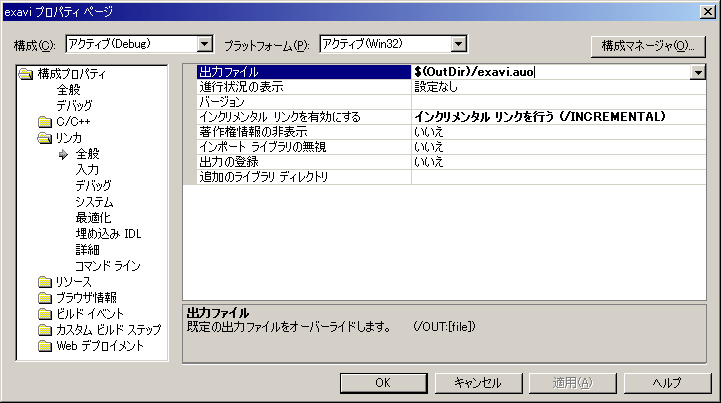
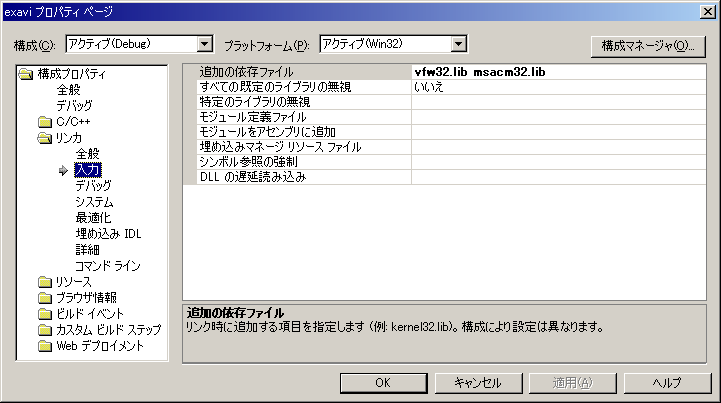
次にプロジェクトのオプション追加。「ソリューションエクスプローラ」からプロジェクトを右クリックして「プロパティ」を選択。出てきたダイアログの「構成プロパティ -> リンカ -> 全般」から「出力ファイル」で拡張子を「dll」から「auo」に変更。[画像]
さらに「構成プロパティ -> リンカ -> 入力」から「追加の依存ファイル」に「vfw32.lib」と「msacm32.lib」を追加。[画像]
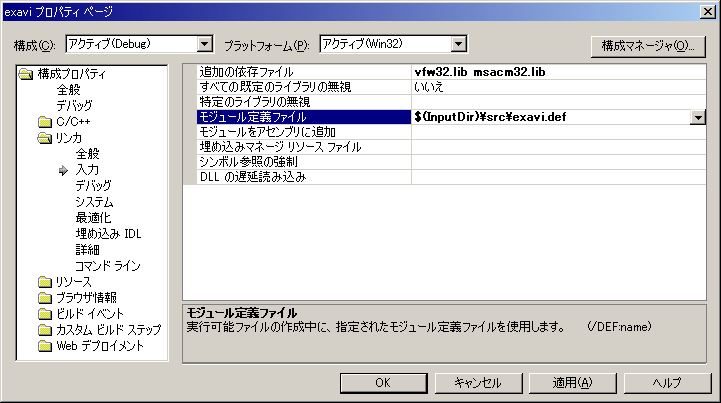
さらに「モジュール定義ファイル」へ「exavi.def」のパスを追加する。[画像]
これで、拡張 AVI 出力プラグインをビルドすることができるようになった。ただし、これだけだとデバッグ版の設定しか済んでいないので、リリース版でもプロジェクトのオプション設定で同様のことをしてあげる必要がある。
元々のメールに書かれていたのは「GetFilterTable ではなく _GetFilterTable@0 でシンボルが公開されてしまい、プラグインとして認識されない」という質問だったので、最後のモジュール定義ファイル設定部分さえ正しく行えば問題が解決しそうな気もしたのだけど、とりあえず最初から一通り書いてみることにした。
最初から独自のプラグインを作る場合は「既存項目の追加」ではなく新規ファイルの追加で地道にソースを作っていくだけで、他は同じにいけるはず。
株の話。新札切り替えの好調で今期末 25 円に増配のニュースが昨日出た、グローリー工業 [6457 : 東証1部] を 100 (一単位) 購入。1699 円。
反省点としては通勤電車内で、AirH" 経由での取引は無謀とか。寄り付き前の値動きに振り回されてしまい冷静な判断ができなかった。昨日購入の株もまだ含み益があるとはいえ、前日比マイナスになっている辺りに不安感。両株とも権利確定までは持つ予定なのだが。
いつか書いておきたかったことだし、メールで要望が入ったので良い機会だというわけで。動き検索についてあれこれ。主に MC+DCT タイプのビデオエンコーダ的視点から。まずは基本となる全検索から。
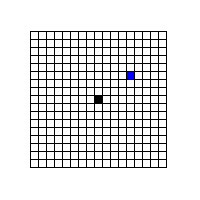
これは英語表記だと、Full Search (全検索) とか Exhaustive Searce (徹底検索) と呼ばれる手法で、愚直に、一定の検索範囲を左上から右下まで一つずつ調べて、コスト (通常は SAD [差分絶対和] を利用する) が最小となる位置を動きベクトルとして採用する手法。
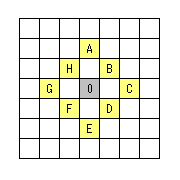
上の図のように、±8 の範囲を検索する場合は、17x17 で 289 個の場所で虱潰しにコスト評価を行い、コストが最小となった場所を MV として採用する手法なわけだ。(黒で塗りつぶした場所が検索中央で、青で塗りつぶした場所が発見されたコスト最小の位置)
この手法の問題点は、膨大な計算量。画像のサイズにもよるけれども、720x480 (いわゆる D1 解像度、DVD と同じサイズ) の場合だとまともな符号化効率を追求する場合は、最低でも ±32 画素の検索範囲が必要になってしまう。その場合の評価パターンは 63x63 で 3869 個にもなってしまう。
実時間でのエンコードを行おうという場合、この動き検索アルゴリズムを採用するとハードウェアの助けを借りない限り不可能ということになってしまう。そんなこんなで、各種高速なアルゴリズムが必要になるわけなのだ。
高速動き検索アルゴリズムとして、一番歴史のあるアルゴリズムが今回のステップサーチ。基本的な考え方は、最初に荒く検索して、段々とより詳細なレベルでのベクトルを探していこうというもの。縮小画像を作るケースと作らないケースがあるけれども、ここではより高速な検索が可能な縮小画像を作る場合について説明してみる。
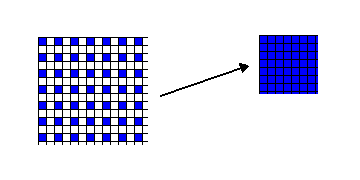
まず、上の図のように、2x2 の 4 画素から、左上の 1 画素を取り出すことで、参照フレームの縮小画像を作る。また MB (マクロブロック) も、同様に 16x16 から 8x8 への縮小を行う。その上で、全検索と同様に、検索範囲の右上から左下までを虱潰しに探し、コストが最小となった位置を中心に、今度は縮小していない原画ベースで、±1 [3x3] の範囲で検索を行って、画素単位でのベクトルを決定する。
原画での ±32 の検索範囲は、縮小画像上では ±16 の検索範囲に相当するので、検索パターン数は 65x65=4225 -> 33x33=1089 と約 1/4 に減少する。また、一つの場所のコスト評価に必要な計算量も、16x16 画素の計算から 8x8 画素の計算で済むようになるので、同様に 1/4 に減少する。つまり、2 ステップでのステップサーチは全検索と比較して 1/16 に計算量を削減できる。これは縮小画像上での 1st ステップの検索に必要な計算量のみを出したものだけれども、2nd ステップの 3x3 範囲の評価に必要な計算量や、参照フレームの縮小に必要な計算量などは元々の計算量に比べれば誤差のようなものなので、検索範囲が広い場合なら無視してもかまわない。
以上は 2 ステップの場合のステップサーチの解説だけれども、さらに縮小画像を増やしていってステップ数を増やすこともできる。ステップサーチは全検索と比較すると劇的な計算量の削減ができるわけなのだけど、それでもいくつかの欠点がある。
全検索と比較すれば劇的な短縮ではあるものの、それでもまだ遅くて、D1 解像度を実時間エンコードなどという場合には使えないことが多い。また、1st ステップの検索で縮小画像を元に大まかな MV を決定してしまうため、1 画素単位の模様がある場合に、非常に不利な MV を見つけてしまうことがある。さらに、インタレース画像への対応を考えた場合、かなり使いにくいアルゴリズムといえる
速度と画質面の問題以外に、知的所有権 (特許) といういやらしい問題が、高速動き検索アルゴリズムには付きまとう。このアルゴリズムに関しては、NEC が特許を持っているという噂を聞いたことがあるのだけど、元々は山形大学の 古閑先生 が NEC 時代に 3 ステップサーチとして考案したもので、論文の公表自体は 1981 年らしい。仮に特許があったとしても既に 20 年以上経過しているので期限切れのはず。安心して使っていいと思う。
今までにあげた検索手法は、とにかく一定の範囲を検索するという手法だった。今回のスパイラルサーチは、MV が存在する確率が高い場所から検索を開始して、コストが充分に小さい MV を発見できたら、そこで打ち切り (Early Termination) を行おうという目論見のもの。とりあえずスパイラルサーチでの検索パターンは次の図のようになる。
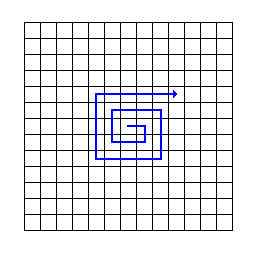
中心からスタートして、螺旋順に段々と範囲を広げながら検索していく手法がスパイラルサーチだ。これだけでは計算量自体は全検索と変わらない (制御が複雑になるだけ厳密には増えてしまう) ので、スパイラルサーチでは検索の打ち切り処理を入れてようやく意味を持つ。もしも MV の存在する大まかな位置がわかるのならば、その周辺を少し調べて充分に小さな MV を検索するだけでそれ以上の検索を止めてしまうことができる。うまく打ち切りができた場合の計算量は全検索に比べて 1/100 以下になる。
この手の打ち切りを伴う動き検索では、初期検索位置 (Initial Search Point) の設定と、打ち切り閾値 (Termination Threshold) 次第で性能が左右される。検索開始位置の設定がまずければ、MV が存在するはずもない場所を無駄に検索し続け、全検索と大差ない計算量になってしまう。打ち切り閾値が大きすぎれば圧縮効率が悪くなるし、小さすぎれば計算量が全検索と変わらなくなってしまう。
まず、検索開始位置の設定について。実際の動画での動きベクトルは (0,0) の位置か周囲の MB が持つ MV の側になることが多い。その為 MPEG-1/2 での MV の記録方法は左隣の MB が持つ MV からの差分という形になっているし、また P ピクチャでは (0,0) ベクトルを特別扱いして小さな符号量で表現できるようになっている。
この MV が持つ特徴から、スパイラルサーチでの検索開始位置は、(0,0) か、PMV の位置が選ばれることが多い。PMV とは各動画フォーマットが MV を (差分 MV の形で) 記録する際に、基準として扱われる MV のことだ。PMV と実際の MV が似ているほど MV を記録するために必要な符号量が小さくて済むようになっている。MPEG-1/2 では、PMV には左隣の MB が持つ MV が使われるし、MPEG-4 では 左・上・右上の 3 つの MB が持つ MV の中央値 (Median) が使われる。
スパイラルサーチを実装する場合、実装が簡単なのは (0,0) からの検索開始になるが、MV に費やされる符号量をできるだけ小さくしたいので、PMV を開始位置に設定する形でスパイラルサーチを実装することが多い。H.264/AVC の JM では、PMV を開始位置に設定する形でのスパイラル検索を基本アルゴリズムとして採用している。(打ち切りが入っていないので、非常に遅い。つーか全検索だし)
この検索アルゴリズムの性能 (圧縮率/速度) は打ち切り閾値に左右される。昔は閾値として固定の値が使われることが多かったのだけど、動画シーケンスやビットレートによって最適な閾値が異なるので、ここ数年は閾値を適応的に変化させようというタイプのものが多い。興味がある人は JVT の公式 FTP サーバ からドキュメントを探して読んでみると楽しいかも。
今回解説するダイヤモンドサーチは、XviD 等最近の MPEG-4 系コーデックで採用されているアルゴリズムの基本となっているアルゴリズム。ダイヤモンドサーチを拡張したものに MVFAST とか PMVFAST とかがあるのだけど、今回は基本となるダイヤモンドサーチのみを解説する。
ダイヤモンドサーチでのサーチパターンは次の図のような形になる。
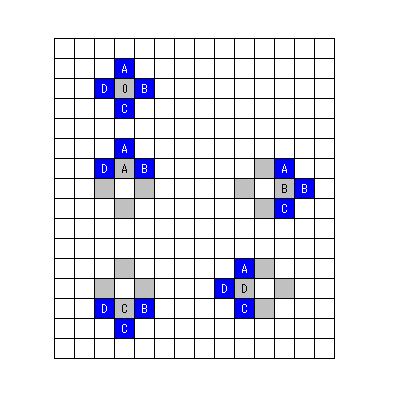
ここには 5 つのパターンを載せている。検索を開始した場合に適用されるパターンは、上段にある、中央に「0」と書かれているパターンだ。まず中央の「0」の位置のコストを評価し、次に「A」「B」「C」「D」の 4 つの位置のコストを評価する。このときに、どのコストが最小になったかで次に適用されるパターンが変化する。
まず「0」がコスト最小となった場合。この場合、検索はそこで打ち切られてストップする。「0」の位置の MV がそのまま MV として決定する。
次に「A」がコスト最小となった場合。この場合、中段左のパターンが採用される。今まで「A」だった位置を新たな検索中心として「A」「B」「D」の位置のコストを評価する。
「B」がコスト最小となった場合、中段右のパターンが採用される。今まで「B」だった位置を新たな検索中心として「A」「B」「C」の位置のコストを評価する。同様に、「C」がコスト最小となった場合は下段左のパターンが採用され、「D」がコスト最小となった場合は下段右のパターンが採用される。
つまり、上下左右の 4 つの位置の検索を行って、中央の位置がコスト最小となるまで (コスト最小の位置が更新され続ける限り) 次々に場所を移って行くのがダイヤモンドサーチになる。パターンを個別に書かずに、実際の検索例を表すと次の図のようになる。
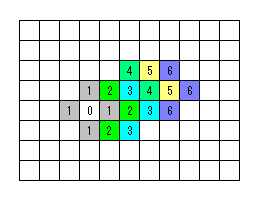
この図では 6 ステップまで計算して MV が確定した例を示していて、サーチパターンの図で言うと「B」「B」「A」「B」「B」と検索が進んだ様子を表している。ダイヤモンドサーチを行う場合、実際ここまでステップ数が必要になることは稀で、80% 程度は 3 ステップ以下で MV が決定してしまう。
既に察しの良い人は気が付いているかもしれないけれども、このアルゴリズムは非常に高速で、全検索と比較して 1/200 程度の計算量で済むようになっている。欠点は符号化効率で、動きの少ない絵ならばさほど問題は無いものの、サッカーやフットボール等の動きの激しいスポーツの絵に対してこのアルゴリズムをそのまま使うと、非常に不幸なことになってしまう。
この検索アルゴリズムでは、スパイラルサーチ以上に、初期検索位置の選択が重要になる。次回、その辺りや MVFAST とか PMVFAST の解説を行う予定だ。
今回解説するアルゴリズムは、MVFAST (Motion Vector Field Adaptive Search Technique) と呼ばれるもので、MPEG-4 エンコーダの高速版を作ろうという MPEG の試みの中で開発され、採用されていたアルゴリズムだ。MVFAST は、ダイヤモンドサーチを実行する際の検索開始位置を、なるべく多くの候補から検討することで、ダイヤモンドサーチの欠点を補おうということを目標にしている。
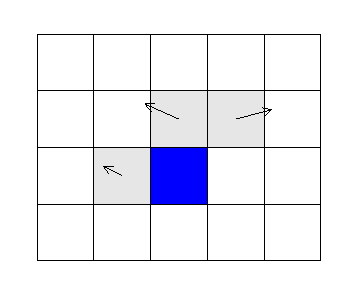
まず、MPEG-4 では、PMV を決定する際、上の図に示すように「左」「上」「右上」の 3 MB の持つ MV から、中心値 (Median) を取る。MVFAST ではこの仕組みを利用する。MVFAST では、(0,0) ベクトル、PMV、左 MB の持つベクトル、上 MB の持つベクトル、右上 MB の持つベクトルで 5 通りの場所で最初にコスト評価を行い、一番コストの低かった場所を検索開始位置としてダイアモンドサーチを行う。また、初期検索位置決定時に充分に低いコストの場所を発見できなかった場合は、次の図に示すパターンを持つラージダイヤモンドサーチを実行して、その後、1 ステップ限定のダイヤモンドサーチを実行する。
ラージダイヤモンドサーチも、(スモール)ダイヤモンドサーチと同様に、検索中心がコスト最小となるまで (最小コストの位置が更新される限り) 検索中心を移動させながら、一定パターンを検索していく手法だ。ラージダイヤモンドとスモールダイヤモンドの違いは、検索パターンで、スモールダイヤモンドが上下左右の 4 点だったのに対し、ラージダイヤモンドは一画素間を空けた上下左右斜めの 8 点を評価する。ラージダイヤモンドは、スモールダイヤモンドよりも速く遠くまで検索することができる。
MVFAST の実際の検索手順を、次のリストに書いてみる。
以上が MVFAST での処理の流れだ。サボれる場合はダイヤモンドサーチすら省略して高速化し、その代わりになるべく多くの初期検索位置を評価して、そのなかで最も成績の良かった場所からダイヤモンドサーチを実行しようという目論見のアルゴリズムで、ある意味判りやすい。どこがフィールド適応なのだろうと突っ込みたくもなるけれど、その辺は FAST というゴロ合わせのために必要だったのだろうと大目に見ることにする。
今回解説する PMVFAST は、前回の MVFAST を拡張したもので、検索開始位置の候補に「直前のフレームの対応する MB を予測する際に使用した MV」を加えたものとなる。
まず、ダイヤモンドサーチでは比較的大きな MV を捕まえることが難しい。例えば、カメラが水平にパンするシーンでは画面全体が、水平方向に大きなベクトルを持つ。しかし、MVFAST では、特に画面端の MB 等の手掛かりが少ない MB で正しい MV を発見することができないことがある。
ところが、カメラのパンというシーンであれば、前後のフレームで MB が持つ MV の相関性は非常に高いだろうと推測できる。このため、検索開始位置の候補として、前フレームの持つ MV を使うことができれば、カメラのパンやチルトといったシーンでも正しい MV を捕まえられるようになるだろう。
こういう目論見で考え出された動き検索アルゴリズムが PMVFAST だ。具体的な検索手順では、MVFAST の、隣接 MB 3 個の MV と (0,0) ベクトルの評価の後に、前フレーム対応 MB の持つ MV の評価が入ることになる。
当然ながら PMVFAST を採用するためには、前フレームの MV を全て記録しておく必要が発生する。エンコーダを作成する際の面倒は増加するけれども、実際に符号化効率は確かに向上するので、この手の前フレームの MV を手掛かりに検索を行うアルゴリズムは多い。
今回は、個別の動き検索アルゴリズムから離れて、MV のビット量について考えてみる。次回に解説する予定の RD (Rate Distortion) の話の下準備として。
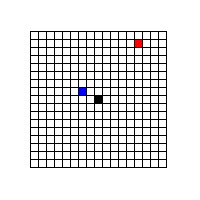
例えば上の図で、赤で塗りつぶした位置は (5,-7) というベクトルで、青で塗りつぶした位置は (-2,-1) というベクトルなのだけれども、赤の SAD と青の SAD が共に 400 で最小値だった場合、どちらを選ぶべきだろうか。(説明を簡単にするために、今回 PMV は (0,0) になっているものとする)
ベクトルは短いほうが可変長符号で圧縮する際に少ないビット数で済むので、この場合 (SAD が等しい場合) は明らかに、より短い MV になる青の位置を採用するべきだ。じゃあ、赤の SAD が 395 で、青の SAD が 400 だったらどうするべきだろうか。
とりあえず、この問題の解答は明日以降に後回しにして、今まで説明してきた「全検索」「スパイラルサーチ」「ダイヤモンドサーチ」の場合で、赤と青、共に SAD が 400 だった場合にどちらが選択されるかを説明してみる。
まず全検索の場合。この場合は不利な長いベクトルを持つ赤の位置が選択されてしまう。なぜなら、赤の位置が左上から右下の検索順でより手前に存在するために最初に出会った SAD 最小の位置が採用されてしまう。これが一昨年の年末に 間違ったデジタル放送の楽しみ方 [4] で書いた MV の問題の原因だったりするわけだ。
次にスパイラルサーチの場合。この場合中心から螺旋順に検索していくので、最初に出会う SAD 最小の MV は青の位置だ。短い MV で済む青の位置が選択される。
最後にダイヤモンドサーチの場合。この場合 60% 程度の確率で青の位置が選択されると思うのだけれども、他の場所の SAD の様子によっては、最初の場所から左に進まず、右に進み始めて明後日の MV を求める可能性もある。ダイヤモンドサーチはある程度大きな模様が MB 内にあれば正しい MV を求める可能性が高いのだけど、細かな模様を持った MB だと、途中で局所的な最小値にはまり込んで動かなくなる可能性があるので。ただ、その場合でも赤に到達する可能性よりも青に到達する可能性の方が高い。
この辺りの事情が、ダイヤモンドサーチという検索範囲の非常に狭いアルゴリズムでも、全検索と勝負が出来る原因になっている。ダイヤモンドサーチでは (0,0) や PMV の側から、なるべくコストが低くなる場所を探し出すアルゴリズムになるので、必然的に MV に使われるビット量は少なくなる。特に、比較的遠くに、ほんの僅かだけコストが下がる場所があるという場合に、そこの位置にはまり込む可能性が少なくなる。
全検索と比べると、DCT 係数などに使われるビット量は増えてしまうけれども、その代わり MV に使うビット量が減るので、トータルでは 5% 程度符号化効率が落ちるだけで済むのがダイヤモンドサーチベースの MVFAST/PMVFAST というアルゴリズムなわけだ。
今回は レート歪 (Rate Distortion - RD) 理論に関して。 去年の 6/26 とか 9/29 とかで書いた話と重複してしまうけれども。
前回に引き続き、この図を例にとって説明してみる。今回は赤の位置と青の位置での SAD が共に最小になる場合ではなく、赤の SAD が 395 で、青の SAD が 400 だった場合にどちらを選択する方が正しいかという問題を扱う。
この手の話は具体的に考えた方が判りやすいので、H.264/AVC での CAVLC での MV ビット量を考えてみる。赤の位置の MV は (5,-7) なので PMV が (0,0) の場合、ビットストリームに記録される DMV は (20,-28) となる。ここで、数値が 4 倍されているのは、H.264/AVC では 1/4 画素単位で MV を記録する為に、画素単位の MV を 4 倍した値を記録することになっている為だ。このとき必要なビット数は 22 ビットになる。
同様に青の位置の MV は (-2,-1) なので DMV は (-8,-4) となって、必要ビット数は 16 ビットになる。赤と青の、MV が消費するビット差は 22-16 で 6 ビット。この 6 ビットを SAD に換算することができて、換算値が SAD の差である 5 を上回れば青を選択するべきだし、下回れば赤を選択するべきだということになる。
まず、RD を考慮することでビットから SAD への変換を行うことは可能だ。実際に H.264 のリファレンス実装である JM では、動き検索時に、QP 値に依存するλという bit -> SAD 変換係数を MV の消費するビット数に掛けることで SAD への変換を行っている。
RD 曲線自体に関しては 6/26 の記述を、λの正体に関しては 9/29 の記述を参照してもらうことにして、この JM で採用されているモデルが前提にしている幾つかの近似をリストアップしておく。
まず、予測誤差と符号化誤差をほぼ等しいものとして近似している件について。RD の元々の定義では、歪は符号化に伴う (デコード結果と原画との) 誤差を表していて、動き補償後の予測誤差とは別物なのだけど、二つの誤差を近似 (DCT 係数は発生しないという前提に) して RD を適用している。実際に動き検索というのは DCT 係数を減らす (全て 0 が理想) ことが目標だったりするので、これ自体はあまり影響しないはず。
次にλの決定方法に関して。レート歪理論というと、その背景には遠大な理論や計算式がありそうに見えるけど、実際のλは、QPとλを一定範囲で振りながら何度もエンコードを実行して、最も成績の良かったλを QP ごとに見つけ出し、QP - λの 2D プロット置いて、適当な近似式を立ててなるべく滑らかにつながるようにしただけで決定できるものだったりする。
最後に。RD 曲線を見ると、歪によってλが変わるべきと感じるかもしれないけれど、JM では QP 毎に固定のλを使っている。これに関しては根拠が少しわからないのだけれども、実装の簡易化やストリーム全体という形で見れば、この方式でも問題ないということなのかもしれない。
前回、RD を考慮することで MV が消費するビット数を踏まえた動き検索ができるという趣旨のことを書いた訳なのだけど、今回は RD とダイヤモンドサーチの相性について。まず、RD とダイヤモンドサーチの相性は決して良いわけではない。
ダイヤモンドサーチの利点は検索範囲が少ないことと、極端に大きな MV を選択することが少ないという 2 つの点なのだけれども、RD を考慮して MV のビット量を検索に反映させる場合、ダイヤモンドサーチの検索範囲はさらに狭くなってしまい、PMV から一歩も動かないというケースが大半になってしまう。ダイヤモンドサーチの仕組みから考えて当然のことなんだけれども。
全検索で RD を考慮して MV のビット量を検索に反映させる場合、全検索の欠点だった「僅かに SAD が低いだけの、極端に大きな MV を採用してしまうことがある」という問題は解決するので、圧縮効率は非常に向上する。ダイヤモンドサーチでも RD を考慮することで圧縮効率が僅かに上昇するのだけど、その改善率は全検索ほどではない。結果、全検索とダイヤモンドサーチとの間の圧縮効率の差は広がってしまう。
かといって、全検索を使っていては現実的なスピードのエンコーダを作ることはできない。次回は JM の FastME について、H.264/AVC がどのようにこの問題に対処しているかという点を解説する予定。2・3 日間が開いてしまうかもしれないけれど。
今回は JM の FastME について。これは Unsymmetric-Cross Multi-Hexagon Grid Search という長ったらしい名前のアルゴリズムで、名前の長さがあらわしているとおり、それなりに複雑なアルゴリズムになっている。処理手順を次のリストに書いてみる。
アンシンメトリッククロスとか、5x5 グリッドとかラージヘキサゴンとかスモールヘキサゴンとか、初めての単語が多いけれども、順に解説していくので我慢して欲しい。
まずは、アンシンメトリッククロスサーチについて。検索パターンは次の図に示すとおり。
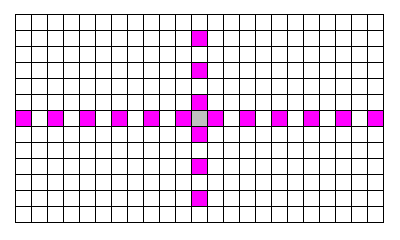
検索開始位置を中心に十字状 (Cross) の検索をするわけなのだけど、このとき水平方向と垂直方向の検索範囲が非対称 (Unsymmetric) に、垂直方向は水平方向の 1/2 の範囲しか検索しないようになっている。通常の動画では、垂直方向の動きよりも水平方向の動きの方が多いのでそれを捕まえやすいようにしているらしい。
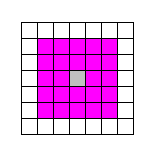
次に実行される 5x5 グリッドサーチについて。これは普通の 5x5 全検索と検索範囲は変わらない。念の為に検索パターンを描いておくと次の図になる。
その次に実行されるラージヘキサゴンサーチについて、検索パターンを次の図に示す。
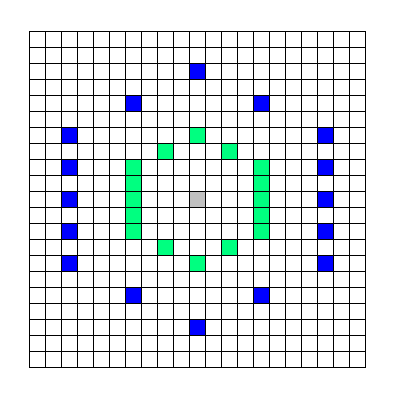
6 角形状に配置した 16 点の検索位置を、中心は移動させずに、放射状に広げていく検索がこのラージヘキサゴンサーチになる。上の図の、灰色で塗りつぶした位置が検索中心で、緑で塗りつぶした位置が 1st ステップの検索パターンで、青で塗りつぶした位置が 2nd ステップの検索パターンだ。(注: 図には 2nd ステップまでしか載せていないけど、実際には 3rd, 4th, .. と検索範囲一杯まで続ける)
この検索の実行中は、1 ステップ広げる毎に最小コストを閾値 A と比較して、閾値 A 未満になればその時点で検索を打ち切る。これは、この検索を無条件に実行し続けるとこの処理が重くなりすぎてしまうため。
スモールヘキサゴンサーチについて、検索パターンを次の図に示す。

これは、ラージダイヤモンドサーチの改善として考え出された検索方法で、ダイヤモンドサーチ同様に、検索中心がコスト最小となるまで検索中心を移しながら検索していくアルゴリズムだ。ラージダイヤモンドでは、1st ステップの実行に 8 ポイントの検索が必要になり、2nd ステップ以降では 3/5 ポイントの検索が必要になるのに対して、スモールヘキサゴンサーチでは 1st ステップに 6 ポイント、2nd ステップ以降でも 3 ポイントのみと検索回数が少なくなる。それでも 1 ステップでの移動距離はラージダイヤモンドと変わらないというのが売り文句になっている。
最後のスモールダイヤモンドサーチについては、既に何度も出てきているので省略する。
この Unsymmetric-Cross Multi-Hexagon Grid Search アルゴリズムを利用すると、コストが充分に小さい MV が発見できた最良の場合だとダイヤモンドサーチだけが実行され、見つけられかった場合だけ周囲を広く探していくという処理になる。必要のない場所では検索をサボり、必要な (コストが高い) 場所ではしっかり探す。しっかり探す場合、近くは厳密に (5x5 グリッドサーチ) 探して、遠くはまばらに (ラージヘキサゴンサーチ) 探す。言われてみると納得してしまう検索方法だ。
実際、圧縮効率を確認してみると RD 考慮全検索と 1% 程度しか劣化しないのに、スピードは非常に向上する。JM で UseFME = 1 設定でエンコードしても遅いという人がいるかもしれないけど、それは JM の コードが腐っている だけだ。
より詳細な実装を知りたい場合、JVT 公式 FTP から JVT-F017 (サーチパターン) および、JVT-G016 (打ち切り閾値) を参照してみると参考になるはず。特に、この検索アルゴリズムでは打ち切り閾値が非常に重要なのだけど、今回の解説では完全に省略してしまっているので実際に試してみたいという人は JVT-G016 を確認することを推奨しておく。
今までは基本的にブロックマッチングベースの解説を続けてきたけど、これとは多少毛色の変わった方法として、勾配法と呼ばれる MV 推定方法がある。本当はこれについても解説できればよかったのだけど、私の頭が悪いせいで、何故この式でベクトルが求まるのだろうと疑問を持ってしまいどうしても納得できないでいるので、解説は省くことにする。
このシリーズを書き始めてから、WEB を検索して、参考になりそうなページを読んでみたり、特許庁の特許 DB から NHK の特許 (特許 2898798) を読んだりもしたのだけど……。正直な感想としては「勾配を求めるよりも素直にダイヤモンドサーチで 4 ポイントの SAD 計算を行った方が PSADBW 使えて速いのじゃないのかなぁ」とか「学術的で研究としては楽しいかもしれないけど、将来の発展は無いんじゃないかなぁ」とか感じてしまったり。
もっとも、私は勾配法関連のプログラムの実装をしたことがなくて、ブロックマッチング系の ME しか実装したことのない人間なので、偏った意見になっている可能性はある。もしこのページを読んでいる人で、勾配法を研究していて気を悪くした人がいれば、反論ページ作るなり、メールを送るなりして欲しい。納得できれば訂正記事を書くので。
動き検索と RD の関連や、全検索とダイヤモンドサーチの利点・欠点、JM の取った対策、一通り書いておきたかったことは書き終わった。長かった動き検索の話も今回が最終回というわけで、多少のまとめを。
前々回までに上げた各種手法の中では、最新の Unsymmetric-Cross Multi-Hexagon Grid が一番、符号化効率・速度の点でバランスの取れたアルゴリズムになっている。
特許が出願されているかどうか知らないけれど、特許とかを気にせずに済む立場の人であれば何も考えずにこのアルゴリズムを使うのが楽なのじゃないかと思う。実績は JM で充分検証済みだろうし。
仕事や研究で動き検索に関わる場合は、このアルゴリズムが当面のライバルになるのじゃないかと思う。そういう意味でも、一度自分で実装してみて、ポイントを把握しておくのは良いことだろう。
特別に参考文献とかを挙げたりはしないけど、このシリーズで書いたことに関して、私が考え出したものというのは一つも存在しない。根気良く探せば誰でも手に入れることができる情報をまとめただけの内容だ。
それでも、手っ取り早く基礎から最近のトレンドまでを抑えておきたい人が時間を節約できる程度の価値はあるのじゃないかと自負してる。そんなわけで、最初にメールをくれた方には、いい機会を与えてくれたと感謝している。
苦節 8 ヶ月。ようやく C24.008-VC1-Spec-CD2r1.pdf を入手できた。これは SMPTE の C24 (映像圧縮技術委員会) で現在規格策定中の WMV の仕様書草案。
昨年 4 月に SMPTE の会員になり C24 にもぐりこんで [詳細] から、延々 ML を眺めるだけで何のアクションも起こさなかったのだけど、たまたま今週眺めていたメールの中に「(FTP とは別に) ドキュメント公開用の WEB サーバを立ち上げたから、この ID/Password でアクセスできるよん」という記述を発見。
そんなこんなで仕様書草案の入手に成功。むーひょっとすると、ML の管理してた方にメール送っていれば FTP のパスワード教えてもらえてたのかしらん。まぁ結果よければそれで良しということで。継続するか悩んでいたけど、今年も会費 $135 を払い込むことにしよう。
というわけで客先の NDA からは自由な立場で VC1 の仕様書を入手できたわけなのだが…… SMPTE の NDA に触れるので、内容について好き勝手に書くことができないのは変わらなかったり。
えーと、そんな人居ないと思いますが「1/20 以降に c24-vc1 に登録したので VC1 のドキュメントサイトが判らない。WMV の仕様書が読みたいけど英語での質問メールが書けない」という人が居る場合、SMPTE の会員であることを証明できる情報を送ってくれれば、URI/ID/Password 教えます。C24 の中の人は、定期的に新規加入者向けの案内メール流すとかしてくれなそうだし。
株の話。とりあえず昨年末からの取引履歴とかをさらしてみる。
1/14 に全部投げてるのは、前日日経平均および NY が大幅に下げて、当日発表予定だった機械受注統計が期待できなかったので含み益があるうちに全部現金化しておこうと考えて。実際には SQ 算出に伴う下支え & 機械受注統計は大幅増で、14:30 から上がっていったわけなのだが……。
1/17 に購入してるのは 1/14 に投げたのを後悔して。とりあえず中長期保有目的で鉄鋼大手と海運株のなかから比較的割安な 2 銘柄 + 株式分割を経験してみたかったのでスカイマークを追加してみたわけなのだが……。その後日本株は下降トレンドに入ってしまい、現時点での含み損が 35000 と 1/14 の利益確定分を食いつぶしてくれているのがアレな点。あと、保有銘柄の中にヤマシナというブタ株代表の存在があるのが……。
ヤマシナについて簡単に解説すると、新株予約権発行・長期貸付金・貸し倒れ引当金コンボとか新株予約権発行・共同事業支出金・長期共同事業支出金コンボの常習会社。現在大株主のエトナ一号投資組合やペンタ・インベストメント・アドバイザーズ・リミテッドはかなりまともな所のようだけど、取締役に室井久磨センセイが居るので未だに安心はできない。まさしく宝くじ同然の銘柄。興味がある人は 有報作ってても株はテクニカル を眺めてみると楽しいかも。
1/21 にスカイマークを追加購入してるのは、どうやら 220,000〜250,000 のボックス相場で株式分割を迎えそうだと判断して。237,000 では割高なので、平均取得単価を下げるべく底近くだと判断した 225,000 で 1 株追加購入。これは 245,000 を超えたら売却予定。
一昨年とは違い、今回のものはフィルタ側ではなくアプリケーション側の開発なのだが……。なんだかフィルタ作るほうが簡単なんじゃないかと思い始めてしまう面倒くささ。
何かやるごとに Release() 呼ぶ必要が発生するし、基本文字列型が WCHAR だし、とにかく IEnum 系を使わないと何もできないし、ICaptureGraphBuilder は中途半端で不便だし。つーかグラフ作るだけで非常に大変。
ちと甘く見すぎていたかもしれない。これはスケジュールに間に合わない悪寒が……。
邪悪な DirectShow プログラミングガイド。フィルタをレジストリに登録せずに使う方法について。想定読者レベルは、DirectShow フィルタを作ったことがあり、DirectShow アプリケーションも作ったことがある人。
HRESULT hr;
IGraphBuilder *graph;
IBaseFilter *filter;
MyFilter *p;
hr = CoCreateInstance(CLSID_FilterGraph, NULL, CLSCTX_INPROC_SERVER, IID_IGraphBuilder, (void **)&graph);
if(hr != S_OK){
// エラー処理
}
p = MyFilter::CreateInstance(NULL, &hr); // この段階では p の参照カウントは 0
if(hr != S_OK){
// エラー処理
}
hr = p->QueryInterface(IID_IBaseFilter, (void **)&filter); // ここでは 1 に増える
if(hr != S_OK){
// エラー処理
}
hr = graph->AddFilter(filter, L"フィルタ名"); // ここで 2 に増える
if(hr != S_OK){
// エラー処理
}
例えば DirectShow を扱う際に、標準では存在しないフィルタを入れる必要が発生したとする。普通はこういうときでも regsvr32 でレジストリにフィルタを登録して……となるわけなのだけど、DirectShow SDK ドキュメントには独自フィルタを登録せずに使う方法があるようなことが書かれている。
実際にどうすれば登録なしで使えるかまではドキュメントには書かれていなかったのだけど、とりあえず上のようなコードを書けば使えることは……普通の人は気がつかないのかもしれないというわけで、書いて残しておく。これができると何が嬉しいかというと「他者に勝手にフィルタを使われずに済む」「インストールが楽になる」「フィルタ環境に悪影響を与えずに済む」等それなりにメリットがある。
コードの解説。とりあえず MyFilter のインスタンス作成について。ここでは判りやすくするために CreateInstance() を呼んでいるけど、実際にはコンストラクタを直接呼び出して構わない。その場合フィルタの実装から CreateInstance() を削除することもできる。それ以外については通常の DirectShow プログラミングと変わらないはずなので省略。