6 月中は H.264 月間にしよーと別ネタの記述を控えていたのだけど、月も変わったことだし、先月 28 日にあった SBI の株主総会 (およびその後の経営近況報告会) のメモなんかを書いておく。当日は仕事を休んで、こんなことをしていた。
759 [2007/06/28(木) 09:41:00 ID:gvpszqeD0] 山師さん@トレード中 <sage> こちらスネーク昨年に引き続き、総会会場への潜入に成功した。 大佐、指示を請う。 771 [2007/06/28(木) 09:42:22 ID:0/EAXK2MO] 山師さん@トレード中 <sage> >>759 なんか叫んでみてw 778 [2007/06/28(木) 09:45:04 ID:gvpszqeD0] 759 <sage> >>771 無茶を言うな、前から4列目でPC叩いてるだけでもかなり変な人なのに。
会場はホテルオークラ。南北線の溜池山王駅 13 番口から出て、アメリカ大使館の前を (警備に立ってるお巡りさんに向こうの歩道使ってくださいと誘導されながら) 通り、9:35 ごろに会場入り。到着時点ではさほど席は埋まってなく、前から 4 列目に座席を確保。
去年は会場到着が遅かったので、出席者の状況とかも見ることができたのだけど、今回はあまり人が入っていないうちに到着してしまったので、どれぐらい来ていたかとかは不明。
814 [2007/06/28(木) 10:00:33 ID:gvpszqeD0] 759 <sage> 総会開始。 816 [2007/06/28(木) 10:06:07 ID:gvpszqeD0] 759 <sage> 監査役会からの報告終了。 828 [2007/06/28(木) 10:12:39 ID:gvpszqeD0] 759 <sage> 前会計年度の報告終了。決議事項の審議開始。 831 [2007/06/28(木) 10:14:16 ID:gvpszqeD0] 759 <sage> うほ、昨年の通り決議事項に関する質問なし。 832 [2007/06/28(木) 10:14:59 ID:gvpszqeD0] 759 <sage> 一号議案、二号議案、三号議案とも可決。 「その他一切の事業を」可決しちゃうかー。 837 [2007/06/28(木) 10:16:57 ID:gvpszqeD0] 759 <sage> 株主総会しゅうりょー。はやいなー。
とまあ、このような形で株主総会自体は 17 分程度で終了。1 号議案は定款変更で、会社の事業目的に「その他一切の事業」というふざけた項目を追加するという内容で、さすがにコレはどーなのよと思っていた (私は否に丸つけてた) のだけど、それも含めてあっさり全議案可決。なお、2 号議案は取締役選任で、3 号議案は監査役選任。こーゆー定款がある企業に投資してるのはどうかなーと思うので、そのうち投資比率を下げようと決心した。
859 [2007/06/28(木) 10:21:15 ID:gvpszqeD0] 759 <sage> いや、そもそも質問する人が居ないのよ。 だーれも質問しないの。会社側からのサクラすらなし。 タプはいかにも突っ込まれたくないといいたげに早口で説明するし 「議案に関係ないのは経営近況報告会で受け付けるから、そっちで 質問しろ」いうし。
総会の雰囲気はこんな感じ。経営近況報告会の方はすでに SBI チャネルに動画が上がってるので、詳細はそちらを確認してもらうことにして、聞いてた間に浮かんだ感想とか。
こーしてみると、何で SBI の株持ってるのか不思議になってくるな。まー含み損を確定損にする勇気がないのと、現在の業績だけはそれなりに信用している (経営者が、過去の資本政策や発言が原因でマーケットから信用されていないため、業績に比較して割安に放置されていると分析している) からなのだが。
| 昨年末残高 | 5,246,996 |
| 期中追加資金 | 600,000 |
| 6 月末残高 | 6,297,823 |
| 運用損益 | +450,827 |
相場の上昇に助けられて、今年前半の成績はボチボチといったところ。もうちっと巧く立ち回れていれば昨年の損害を取り戻すこともできたのだろうけど、欲を出してホールドを続けたため、昨年の損失の半分を取り戻すのが精々になってしまった。なんとか今年中に浮上したいのだけど、難しそうだよなー。
投機ネタの報告も済んだので、H.264 話に復帰。今回は --direct オプションについて。
とりあえず --interlaced を指定した状態では --direct none と --direct spatial のいずれかが、--interlaced を指定していない状態では --direct temporal と --direct auto が none/spatial に加えて指定可能になる。前回 の設定から、--direct spatial を --direct none に変更した場合のログは以下のものになる。
x264 [info]: using cpu capabilities MMX MMXEXT SSE SSE2 3DNow! x264 [info]: slice I:2 Avg QP:18.00 size: 68548 PSNR Mean Y:42.50 U:44.05 V:45.18 Avg:43.07 Global:42.86 x264 [info]: slice P:182 Avg QP:20.00 size: 39608 PSNR Mean Y:40.77 U:42.90 V:44.00 Avg:41.48 Global:41.38 x264 [info]: slice B:76 Avg QP:21.00 size: 28496 PSNR Mean Y:39.53 U:41.58 V:42.31 Avg:40.19 Global:40.14 x264 [info]: mb I I16..4: 4.6% 72.5% 23.0% x264 [info]: mb P I16..4: 0.5% 16.9% 6.7% P16..4: 37.1% 21.3% 16.4% 0.0% 0.0% skip: 1.2% x264 [info]: mb B I16..4: 0.0% 0.9% 1.9% B16..8: 59.7% 15.6% 21.8% direct: 0.0% skip: 0.0% x264 [info]: 8x8 transform intra:68.5% inter:56.3% x264 [info]: ref P 46.7% 42.2% 4.4% 2.8% 1.8% 2.0% x264 [info]: ref B 48.5% 41.1% 4.0% 3.2% 1.9% 1.3% x264 [info]: SSIM Mean Y:0.9701649 x264 [info]: PSNR Mean Y:40.418 U:42.523 V:43.519 Avg:41.114 Global:40.987 kb/s:7316.42 encoded 260 frames, 2.68 fps, 7316.84 kb/s
注目すべきは、次の 1 行。
spatial> x264 [info]: mb B I16..4: 0.0% 0.8% 1.7% B16..8: 28.7% 13.4% 25.8% direct: 9.3% skip:20.2% none > x264 [info]: mb B I16..4: 0.0% 0.9% 1.9% B16..8: 59.7% 15.6% 21.8% direct: 0.0% skip: 0.0%
--direct none を指定した場合、mb B の行に表示される direct: 0.0% と skip: 0.0% から、ダイレクト MB および、スキップ MB が利用されなくなっていることが読み取れる。
ダイレクト MB が無くなるのは当然として、なぜスキップ MB まで無くなってしまうかというと、B スライスのスキップ MB というのは、「ダイレクト MB で、予測差分が DCT および量子化の結果、全部 0 になってエンコード結果には出力されなかったもの」という扱いなため。なので --direct none でダイレクト MB を無効にすると、それに影響されてスキップ MB も使えなくなってしまう。
で、スキップ MB というのは MB の消費ビットが 1 bit 未満で済む、消費ビット的に (RD 性能的にも) 重要な機能だったりするので、これが使えなくなってしまうと圧縮効率が落ちてしまう。特に良好なソースで動きの少ないシーンであれば、大半がスキップ MB にできるところを、わざわざ 16x16 とかで MB モードや参照インデックスやら差分 MV で余計なビットを使うのだからその弊害は大。
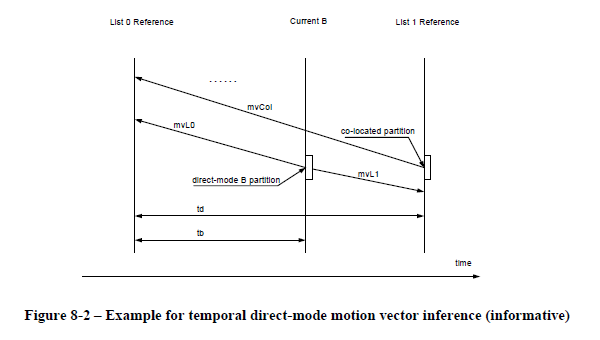
--direct temporal と --direct spatial の違いは、ダイレクト MB の MV を、時間軸での近傍 MB を参照 (temporal direct : 時間ダイレクト) して決定するか、同一フレーム内での近傍 MB を参照 (spatial direct : 空間ダイレクト) して決定するか。
時間ダイレクトモードについての、判りやすい図が勧告書の中にあるので、引用。こんな形で、直近フレームの対応 MB の持つ MV を引き継いで、時間軸上での位置で補正した MV を使うのが時間ダイレクトモードで、PMV を求めるときと同様の仕組みで、近傍 MB (左・上・右上 の 3 ブロック) のもつ MV の中央値をとった MV を使うのが空間ダイレクトモードになる。
時間ダイレクトモードは動きが少ないシーンで有利に働き、空間ダイレクトモードは動きの多い (OP 等の) シーンで有利に働く。どちらのモードを使うかはスライス単位でしか切り替えることができないのだけれど、--direct auto を指定した場合は、シーンに応じてエンコーダがどちらのモードを使うかを選択してくれる。マルチパスの場合は stats ファイルからデータを読んでどちらのモードを使うか決定するし、シングルパスの場合でも、直前のフレームで、時間ダイレクトと空間ダイレクト、どちらの方がスキップ MB にできる割合が高かったかで判定するというロジックになっている。
昨日 --direct を取り上げたので、今日は --direct-8x8 を。といっても、このオプションにはあまり意味がないのだけど。
--direct-8x8 で 0 を指定した場合、シーケンスパラメータセット (sequence_parameter_set : SPS) の direct_8x8_inference_flag というパラメータの値が 0 に設定され、1 に設定した場合は 1 になる。direct_8x8_inference_flag は 丁度一年前 にちっとばかし愚痴をこぼしたことがある。
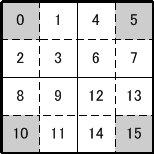
丁度いいので画像を流用する。H.264 では、ひとつのマクロブロック (16x16 ブロック) を最も小さく分割した場合 16 個の 4x4 ブロックに分割して、それぞれに異なる動き情報を持たせることができる。そして direct_8x8_inference_flag は B スライスのダイレクト MB (およびスキップ MB) に動き情報を 8x8 ブロック単位で持たせるか、それとも 4x4 ブロック単位で持たせるかをデコーダに通知するためのフラグとなっている。direct_8x8_inference が 0 の場合は 4x4 単位に異なる MV を持たせることができ、1 の場合は 8x8 単位に異なる MV を持たせるようになる。
もちっとしつこく説明すると、direct_8x8_inference_flag=0 の場合は、上の図で、0〜15 までの各ブロックが異なる MV を持つことができて、direct_8x8_inference=1 の場合は、上の図で [0〜3|4〜7|8〜11|12〜15] という 4 つの 8x8 ブロック単位でしか MV を持つことができなくなる。
ただし、ダイレクト MB の MV 決定方法を考えると、4x4 単位で MV をもててもあまりうれしいことはなかったりする。
x264 のデフォルトの空間ダイレクトモードでは、そもそも MV 自体が 16x16 ブロックの PMV の決定方法と同様の手法で決められるので、サブブロックが異なる MV を持つことが少ない。(ここで「ない」じゃなくて「少ない」にしているのは colZeroFlag という邪悪なものの存在で、時間ダイレクト風味に MV が決定される場合もあるため)
時間ダイレクトモードならば、直近スライスの対応 MB で 8x4/4x8/4x4 モードが使われていれば、8x8 よりも小さいサイズで MV を持つこともあるのだけど、x264 でそのモードを使うためには --partitions all とか p4x4 とかを指定しなければいけない。その辺を指定した場合にどーなるかは既に説明済み。
さらに追加すると、direct_8x8_inference_flag=1 ならば、ダイレクト MB でも 8x8/4x4 DCT が選択可能になるのだけど、direct_8x8_infernece_flag=0 ならば 4x4 DCT 固定になってしまう。
x264 の --direct-8x8 のデフォルトは level>=3 なら 1 にして、level<3 なら 0 という扱いなので、普通に 720x480@29.97 程度 (level=3 相当) の動画をエンコードしている場合ならば、常に direct_8x8_inference_flag=1 で動いているはず。心配な人は明示的に --direct-8x8 1 を指定した方が安全だろうけど。
7 月新番組の「ドージンワーク」を観るのが辛い今日この頃。一話目で視聴中止を考えさせてくれるっつーのはこー珍しいよね。「ななついろ」や「ZOMBIE-LOON」はそれなりに観れそうなのが救いだけど。
本題。x264 の --weightb オプションは、B スライスの双方向予測時に、重み付き予測 (weighted prediction) を行うというもの。--bframes で 2 以上の B スライスを指定している場合に意味を持つ。
厳密には複数参照フレームも考慮すべきなんだけど、とりあえず説明を簡易化するために --ref 1 の参照フレーム数 1 の場合だけを考えることにする。上記のフレーム順 (表示順) で B1 の MB を、P0 および P3 から予測する場合、MPEG-4 まで (および重み付き予測なしの H.264) は次の式で予測画素を作っていた。
予測画素 = (P0 の画素 + P3 の画素 + 1) >> 1
B2 を予測する場合も、同じ式を使う。で、H.264 で導入された重み付き予測では、平均するだけじゃなくて、時間的距離に応じて P0 と P3 の画素に重みを乗せてから予測画素を作ろうということで、次の形に式が変形する。
B1 の予測画素 = ((P0 の画素 * 21) + (P3 の画素 * 43) + 32) >> 6 B2 の予測画素 = ((P0 の画素 * 42) + (P3 の画素 * 22) + 32) >> 6
微妙に係数が変わっているけど、距離に応じて、1/3 と 2/3 の重みを付けて予測画素を作ろうというのが基本的な趣旨。係数が微妙に変化しているのは、逆数を取って固定小数点で処理する際の演算誤差に起因するもの。
それなりに効果はあるのだけど、処理負荷が上がるので、エンコード環境の計算力や、デコード環境 (大抵の Main/High プロファイル対応デコーダなら対応しているはずだけど、Baseline もどきの QuickTime は未対応かも) で ON/OFF を決めるのがいいと思う。
この話は --deadzone-intra/inter の直後にやるのが適切だったかも。まー過ぎてしまったことは仕方がないと開き直って --trellis オプションの話。
このオプションを指定すると「量子化の丸め制御を RD が最適になるように MB 単位で自動的に決定する」という処理が有効になる。また --deadzone-intra/inter オプションは無視されるようになる。
正しく、判りやすく説明できるか自信がないけど、一応 trellis アルゴリズムの詳細を説明してみる。
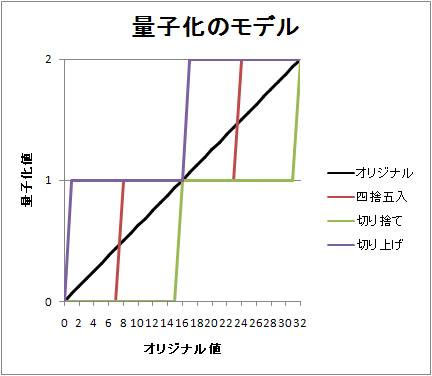
上の図は量子化の処理の概要を示したものになる。簡単に言ってしまえば、量子化というのは整数での割り算で、大きな値を圧縮しやすい小さなスケールに縮小するという処理だ。整数の割り算なので、余りが出た場合、上の値に切り上げるか、下の値に切り下げるかのどちらかを選択しなければいけない。この図はオリジナルの値を 1/16 のスケールに量子化する際に、丸め方式の違いで量子化値がどちらの値になるかということを示したものだ。
さて、丸めによって失われた端数は量子化誤差になる。量子化された値は、実際に利用する際には逆量子化という処理を経て元のスケールに戻してやる必要がある。簡単に言ってしまえば、逆量子化というのは整数の掛け算で、量子化の際に割った値を掛けるだけの処理だ。図の例だと、逆量子化は、量子化値に 16 を掛けるという処理になる。
丸め方法が四捨五入だった場合で、オリジナル値が 10 だった場合、量子化値は 1 になり、逆量子化値は 16 になる。この場合、量子化で失われた
--deadzone-intra/inter オプションは、丸め方法を四捨五入と切り捨ての間で 32 段階 (0 を指定すれば四捨五入になり、32 を指定すれば切り捨てになる) で調整するためのものだった。
ここまでは以前の復習で、ここからが --trellis のアルゴリズム詳細の本番。基本的に量子化後の値というのは絶対値が小さければ小さいほど消費ビットが少なくて済む。なので、丸め方法が切り捨てに近ければ近いほど発生データ量は減る。ただし、丸め方法が切り捨てに近ければ近いほど、量子化誤差は (統計的には) 増えて画質の劣化が大きくなる。
統計的な量子化誤差に関しては簡単に確認することが可能で、オリジナル値が 0〜16 まで 1 つずつあった場合の量子化値および逆量子化値、量子化誤差を求めて、量子化誤差を足し合わせればそれだけで求めることができる。実際に計算してみると、四捨五入の場合は量子化誤差の和が 64 になるのに対して、切り捨てと切り上げでは 120 になって、四捨五入の方が統計的な量子化誤差を最少にすることを確認できるはず。
で、量子化後の係数をどちら側に丸めるかを決定するのに、固定の丸めオフセットを与えて自動的に決めるのではなく「1 係数毎に量子化誤差と消費符号量を求めて RD の観点から最適な方を選択する」のが --trellis 指定時に有効になる処理の基本的な考え方だ。
具体的な処理は次のリストの手順になる。(実装されているのは encoder/rdo.c の quant_trellis_cabac() 内)
CABAC の消費ビット量を推定するの為の処理で問題の関数はかなり複雑な形になっているので、上のリストの手順が正しいものかどうかちょっと自信がないのだけど、多分そんなに外れてはいないはず。
量子化処理はデコーダには依存しないので、--trellis オプションはプロファイル/レベルと無関係に何時でも指定することができる。問題は単純な丸めオフセットを設定するだけの --deadzone-intra/inter と比べると非常に処理が重くなってしまうところなので、これもやっぱりエンコード環境の CPU 速度に応じて選択すべき項目になる。
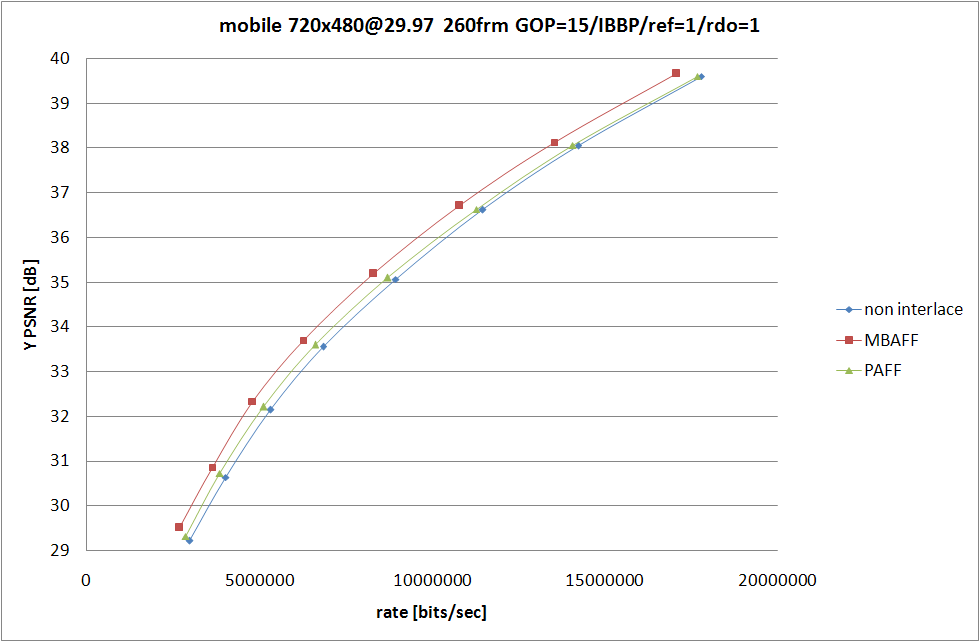
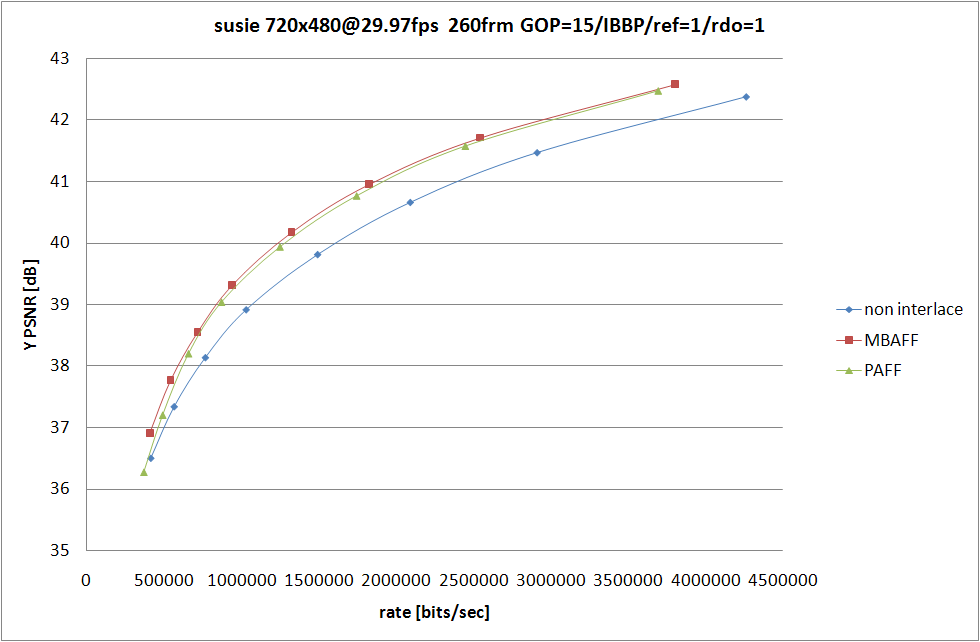
MBAFF と PAFF の違いを。MB 単位でフィールド/フレームを切り替えるか、ピクチャー単位でフィールド/フレームを切り替えるかの違いになるので、動きの大きい (全てをフィールドとしてエンコードした方が良い) シーンでは PAFF の方が効果が高い (MB ペア単位でフィールドフラグを符号化する必要がなくなるため) けど、それ以外の場合は MBAFF の方が符号化効率が高くなることが多い。
|

|
|

|
実際に RD グラフを書いてみれば、そのとおりになっていることは確認できる。動きの大きい football では PAFF の方が RD 性能が高くなっているけど、mobile および susie では MBAFF の方が RD 性能が高くなる。
エンコーダを実装する側から考えると、PAFF の方が同一フレーム内でフィールド/フレームが混在することが無いため、フレームのエンコード処理の実装は楽になる。その代りフィールド/フレーム判定用の処理を先に実行しなければいけなくなるけれども、シーンチェンジ検出や適応 B 判定の為の処理が既に入っているのであれば、そこで同時に判定できるので、さほど実装負荷は高くない。PAFF しか対応しないものが多いのはその辺に理由があるのではないかと考えている。
えー、前回 JM を動かしたときと比較すると大分消費時間が減っているけれども、これは前回ははずすのを忘れていたオプションを OFF にしたため。ChromaMCBuffer を 0 にして消費メモリ量を減らしたのと、BiPredMotionEstimation を 0 にして無効に、AdaptiveRounding も 0 にして無効にしているため。特に ChromaMCBuffer=0 にしてスワップが発生しないようにできたのと双方向動き検索を無効にしたのが効いているはず。
H.264 では、MPEG-1/2/4 までとは異なり、動き補償 (予測) の際に複数の参照フレームを利用することができる。x264 の --ref オプションは何枚のフレームを参照するかを指定するためのものだ。
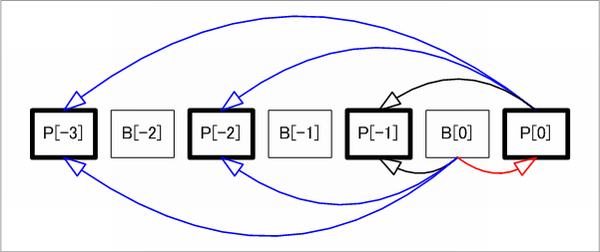
上の図は --bframes 1 で --ref 3 かつ --bpyramid を指定しない場合の参照フレームの様子を示したもの。P[0] をエンコード (デコード) する際には、P[-1] 〜 P[-3] を参照することができて、B[0] をエンコードする際には P[0] と P[-1] 〜 P[-3] を参照することができる。
MPEG-1/2/4 では、図中で黒および赤の矢印で表される参照しかできなかったのに対して、H.264 では青の矢印で表される参照を持つことができる。黒および青で示した矢印は、H.264 用語で L0 予測と呼ばれ、赤で示した矢印は L1 予測と呼ばれる。H.264 の規格自体は L1 予測として P[-1] 〜 P[-3] を使うこともできるのだけど、x264 は L1 予測として P[0] しか使わないように制限している。
x264 [info]: ref P 88.9% 7.2% 3.8% x264 [info]: ref B 89.7% 7.2% 3.2%
エンコード終了時に表示されるログのこの部分は、各 MB がどのフレームを参照したかの割合を示している。この場合一番近い P[-1] を参照しているものがもっとも多く、P[-2]、P[-3] と進むに従って参照率が減っていく。時間的に近いフレームほど似ている部分を見つけやすいので参照確率が上がるのはある意味当然なのだけど。
複数参照フレームが最も効果を発揮するのはフラッシュが多用されている映像で、例えば図で P[-1] がフラッシュでホワイトアウトしているようなシーケンスだった場合、P[-1] も P[0] もほぼすべてイントラ MB としてエンコードするか、あるいはシーンチェンジとして IDR フレームとしてエンコードするかのどちらかしかなくなってしまう。けれども、複数参照フレームが利用できれば P[0] をエンコードする際に P[-2] を参照することで、より効率のよい符号化ができる。
次に効果が出るのは背景の上で物体が動いてるような場合。例えば野球の映像とかでスタンドの前をボールが飛んでいく場合とか。
ボールの場所というのは各フレームで全然別の場所になるし、ボールと同じ MV を持たせて動き保障をさせる場合でも背景部分を符号化してやる必要があるしで、ボール自体に関してはイントラ MB として符号化した方がマシなことの方が多いのだけど、問題は直前フレームにはボールがあったけど、現在のフレームでは背景だけになっている部分。専門用語でこーゆーのを uncovered background (覆いがはずれた背景) とか呼ぶのだけど、これは複数参照フレームでさらに前のフレームを参照してしまえばよく似た部分を見つけて回避することができる。
で、MB 全体で同じフレームを参照すれば済む場合以外の為に、H.264 では 8x8 サブブロック単位で別々の参照フレームを見ることができるようになっている。--mixed-refs はその機能を有効にするか、それとも MB 単位でしか参照フレームを切り替えないかを選択するためのオプション。
フラッシュのシーンだけ救えれば十分だという場合は --mixed-refs を指定する必要はないだろうけど、uncovered backgroud を救いたい場合は --mixed-refs を指定した方がよいはず。MB の一部だけに差し掛かる物体の場合は 8x8 単位で別々の参照フレームを使えた方がより効率の良い符号化ができるはずなので。
このシリーズの 最初で速度差および RD 性能差については言及済みなのだけど、今回は --subme オプションの数字を 0〜7 まで変更した場合に、実際の処理はどう変わるかについて。
| subme | モード判定前 | モード判定 | モード判定後 | 備考 |
| 0 | 画素単位の検索のみ | SAD + MVCOST | 1/2 画素で 1 回検索 | 1/4 画素予測は使わず、コスト評価も SAD のみ 最も軽い (けど指定できない) |
| 1 | 画素単位の検索のみ | SAD + MVCOST | 1/2 画素で 1 回 1/4 画素で 1 回検索 |
--help で表示される中では最も軽い |
| 2 | 画素単位の検索後 1/2 画素で 1 回検索 |
SATD + MVCOST | 1/4 画素で 1 回検索 | 1/2, 1/4 画素検索で SATD を使い始める |
| 3 | 画素単位の検索後 1/2 画素で 1 回検索 |
SATD + MVCOST | 1/4 画素で 2 回検索 | モード判定後の 1/4 画素検索が 2 回に増える |
| 4 | 画素単位の検索後 1/2 画素で 1 回 1/4 画素で 1 回検索 |
SATD + MVCOST | 1/4 画素で 2 回検索 | モード判定前に 1/4 画素まで 検索するようになる |
| 5 | 画素単位の検索後 1/2 画素で 1 回 1/4 画素で 2 回検索 |
SATD + MVCOST | 1/4 画素で 2 回検索 | モード判定前の 1/4 画素検索が 2 回に増える |
| 6 | 画素単位の検索後 1/2 画素で 2 回 1/4 画素で 2 回検索 |
RDCOST | なし | モード判定に RDO を使う |
| 7 | 画素単位の検索後 1/2 画素で 2 回 1/4 画素で 2 回検索 |
RDCOST | RDCOST で 1/2 画素を 2 回 1/4 画素を 2 回検索 |
モード判定後に RDCOST で MV の精度向上を行う |
--subme で変更されるのは、モード判定前に 1/2, 1/4 画素検索をどこまで行うか、その際に用いるコスト評価関数は SAD / SATD のどちらを使うか、モード判定に RDO (Rate Distortion Optimization : 符号量 画質劣化 最適化) を使うか、それとも動き検索で求めたコストをそのまま使うか、モード決定後に追加検索をどの程度行うか、以上の 4 項目になる。
モード判定というのは、例えば P スライスならば I16x16〜I4x4, P16x16〜P4x4 までの様々な MB モードが (--partitions オプションで許可していれば) 利用可能だけれども、実際にどのモードを採用するべきかを判定する処理のこと。この処理がどの程度かしこいかによってエンコーダの性能は大きく影響され、例えば JM の場合はモード選択に RDO を使うか使わないかで 1dB 近く RD 性能が変化する。[RD グラフ例]
で、--subme ではモード判定前にどこまで動き検索を行うかが変更される訳なのだけど、より精度の高い MV を見つけてから判定した方が正しいモードを選択しやすくなるけど、評価対象の全モードで実施される処理なので、それだけ計算量は増えてしまう。--subme 0〜5 までは、基本的に数字が増えるほどより精度のよい MV を検索してからモード選択に入るようになっている。
モード判定方法は --subme が 0〜1 であれば SAD + MVCOST、2〜5 であれば SATD + MVCOST、6〜7 であれば RDCOST と変化する。各方法で最も低い数値となったモードが採用される。
SAD というのは Sum of Absolute Difference の略で、原画と予測画素の間で差分絶対和を取っただけのもの。最近の CPU ならば専用命令が用意されているので、非常に高速に算出することが可能。
SATD というのは Sum of Absolute Transfered Difference の略で、原画と予測画素の間で差分を取った後で、差分にアダマール変換 (DCT の親戚のようなもの、DCT よりも軽い) を掛けて、変換結果の係数の絶対値和を取ったもの。SAD に比べると重いけど、エンコード時に発生するだろう DCT 係数 (の消費する符号量) をよりよく反映したコストを算出することができる。
MVCOST というのは MV が消費するだろうビット数に RD 変換係数 lambda を掛けたもので……詳細についてはこの辺りとかを参照のこと。
RDCOST というのは、MB に対して、予測誤差の算出 -> 整数変換 -> 量子化 -> 逆量子化 -> 逆変換 -> 複号画素作成と実際のエンコード時の処理と完全に同じことを行い、復号画素と原画の間で差分自乗和 (SSD - Sum of Square Difference) を求め、さらに CABAC/CAVLC でのビットストリーム構築まで行って発生ビット量を厳密に求めたもののこと。
RDCOST = SSD + lambda * bits
RDCOST の算出式自体は上記の単純なものだ。差分自乗和 SSD は画素数で割ると MSE (Mean Square Error - 平均自乗誤差) になり、
モード判定前後の 1/2, 1/4 画素の動き検索に書いている回数というのは、ダイヤモンドサーチを最大何ステップ実行するかを意味してる。--subme 5 ではモード判定前に 1/2 画素で 1 回、1/4 画素で 2 回検索することになっているけど、これは移動幅 1/2 画素で 1 ステップ限定のダイヤモンドサーチを行い、さらに移動幅 1/4 画素に変更して 2 ステップ限定のダイヤモンドサーチを行うという処理になる。
JM ではモード判定後の追加検索は存在せず、モード判定前に 1/2 画素で周囲 8 点の検索を行い、引き続き 1/4 画素で周囲 8 点の検索を行うという処理になっているのだけど、x264 の --subme 1〜5 ではモード選択前の処理を軽くして、その埋め合わせとしてモード決定後の追加検索で MV の精度を向上させるという処理になっている。おそらく、この仕組みの方がトータルの処理時間の削減と RD 性能の低下で利益が出るという判断が成立し、採用されているのだろう。
--subme 6/7 で I/P スライスでは RDO が有効になるものの、B スライスでは RDO は無効にされた (--subme 5 と同じ処理が実行される) ままとなる。RDO を B スライスで有効にするオプションが --b-rdo になる。
|
|
|
|
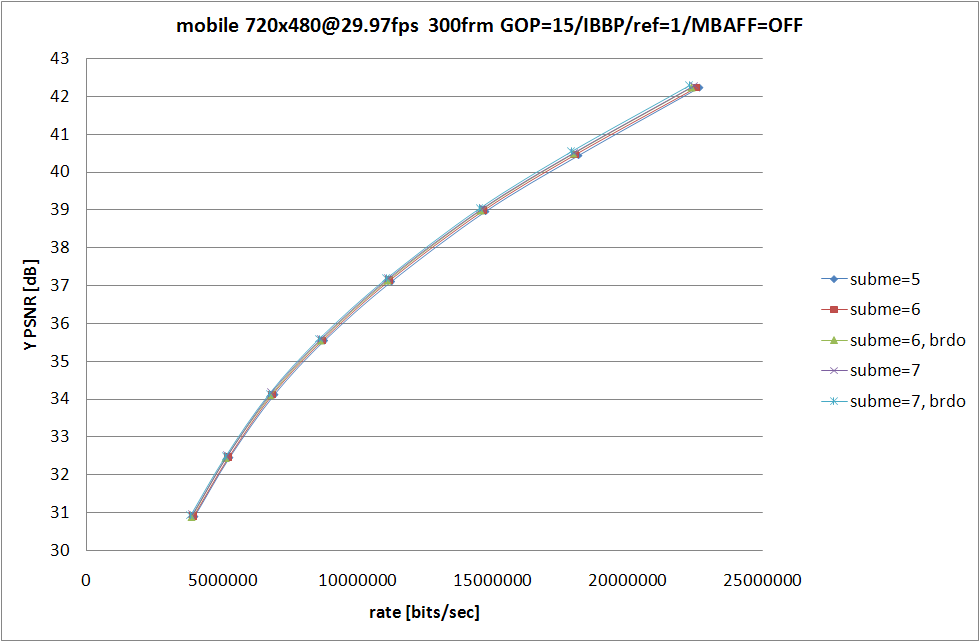
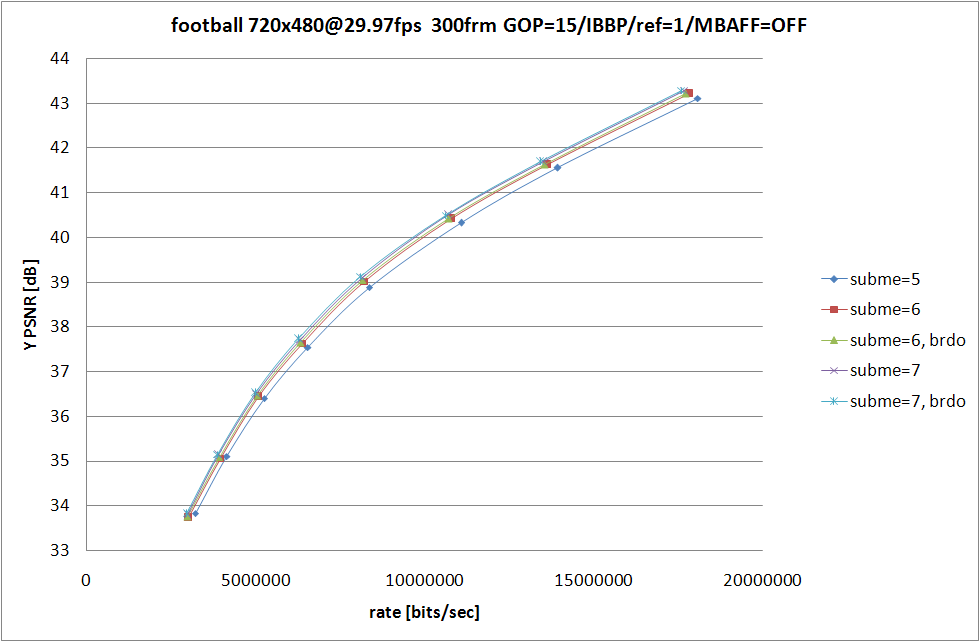
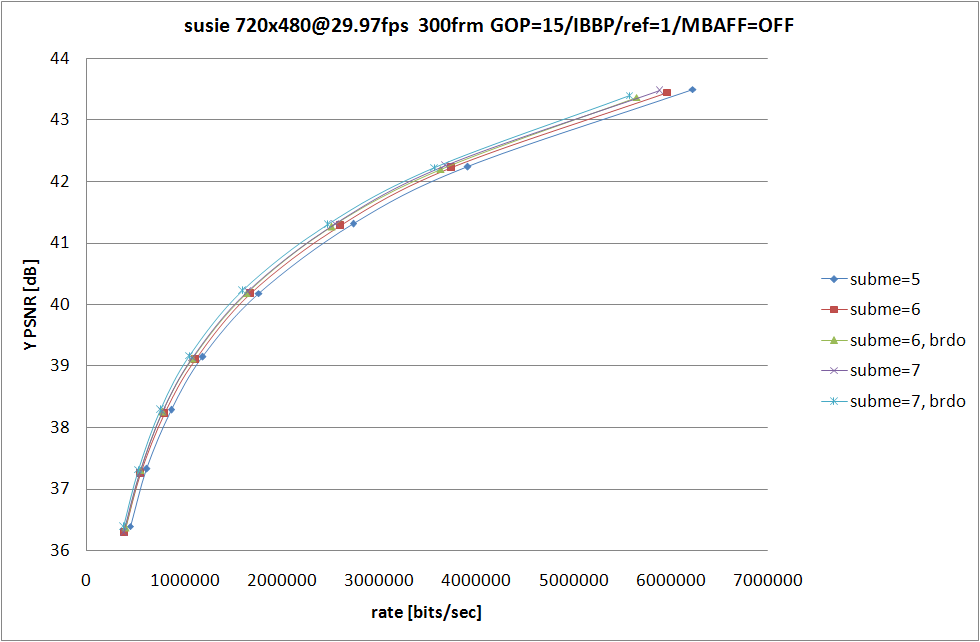
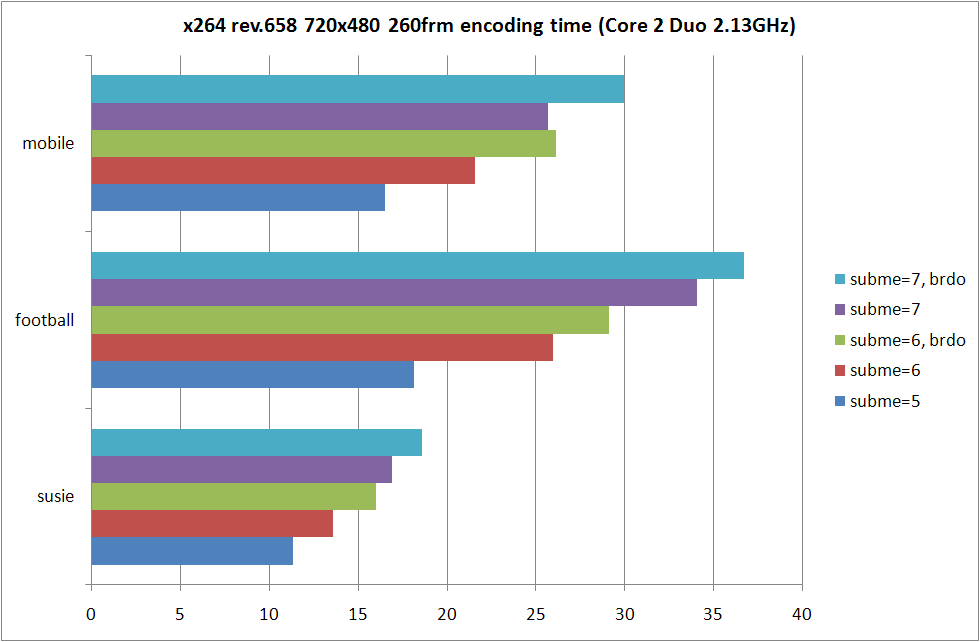
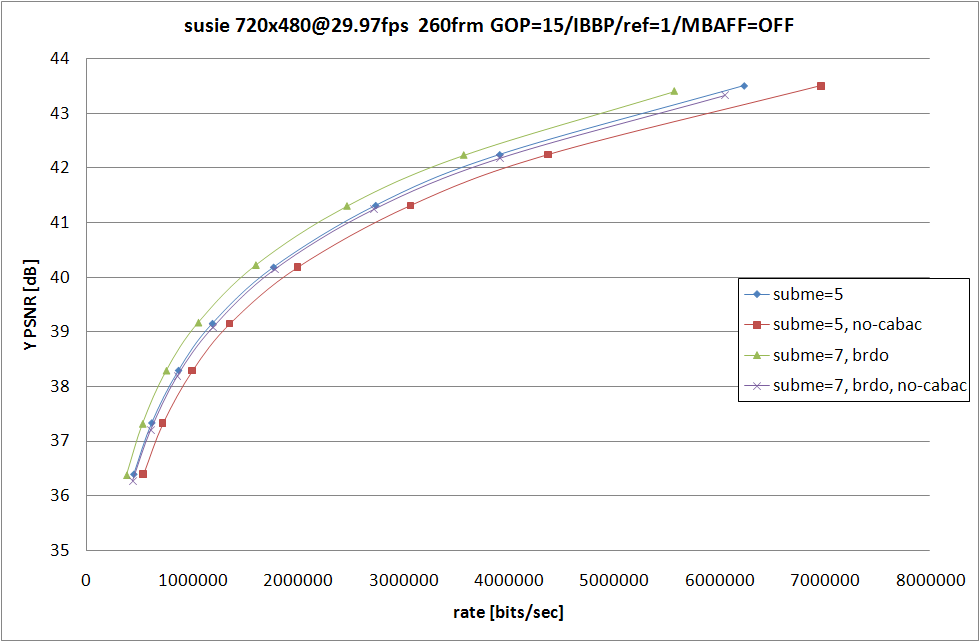
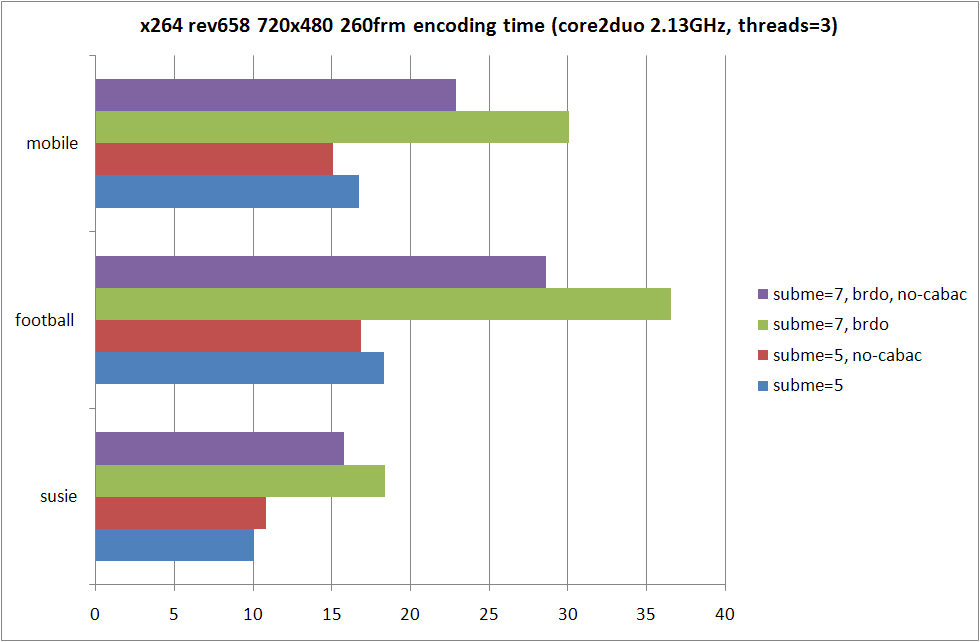
RD グラフおよび、消費時間の比較は以上の形になる。--b-rdo を指定しないよりも指定した場合の方が RD 性能は高くなるものの、--subme 7 と --subme 6 --b-rdo との差はソースに依存する形になっている。
susie のように動きがすくない動画では --subme 6 --b-rdo が --subme 7 とほぼ同等の RD 性能を示しているのに対し、football および mobile では --subme 7 の方がよりよい RD 性能を示している。
RDCOST = SSD + lambda * bits
基本的に RDO は上の式が示すとおり、RDCOST が最小になるもの、つまり、多少画質劣化 (SSD) が増えても発生符号量が少ないものを選ぶという処理になってしまうので、画質よりも発生符号量を重視したい B スライスでこそ価値のある処理なのじゃないかと考えたりもする。もちろん RDO 無効時の
今回の評価で使ったオプションは以下のもの。JM との比較目的であえて圧縮効率の落ちるオプションを指定していたりもするので、真似はしない方がよい。
--keyint 15 # GOP 長 15
--min-keyint 15 # x264 内部で 8=(15+1)/2 に丸められるので意味がない
--scenecut 0 # なので、シーンチェンジ検出を実質無効に
--bframes 2 # IBBP
--no-b-adapt # B/P 適応切り替えを無効に
--ref 1 # 参照フレームは 1 枚に制限 (マルチレフ無効)
--ipratio 1.0 # I は P と同じ QP を使う
--pbratio 1.0 # B も P と同じ QP を使う
--me umh # 画素単位の検索パターンは umhex
--merange 32 # 画素検索時の検索範囲は ±32 画素
# 16 に丸められるのは hex/dia の場合なので設定値は有効
# 意味がないという以前の記述は勘違いによるもの
--no-fast-pskip # P スライスではスキップ判定できた MB でも動き検索を行う
--no-chroma-me # 色差を動き検索に使わない
--8x8dct # 8x8 変換を有効に
--partitions "p8x8,b8x8,i8x8,i4x4"
# p4x4 以外はすべて有効に
--direct temporal
# 時間ダイレクトモードに限定
--cqm flat # flat 16 マトリックスを利用
--threads 3 # 自動検出が正常に動いてないようだったので、明示的に指定
--no-ssim # SSIM を算出しない
--no-psnr # PSNR を算出しない
--no-chroma-me は 1/2 1/4 画素動き検索の際に、色差情報をも含めた検索を行うかどうかを指定するためのオプション。指定しない場合は色差 (U/V) を動き検索に利用し、指定する場合は利用しなくなる。
|
|
|
|
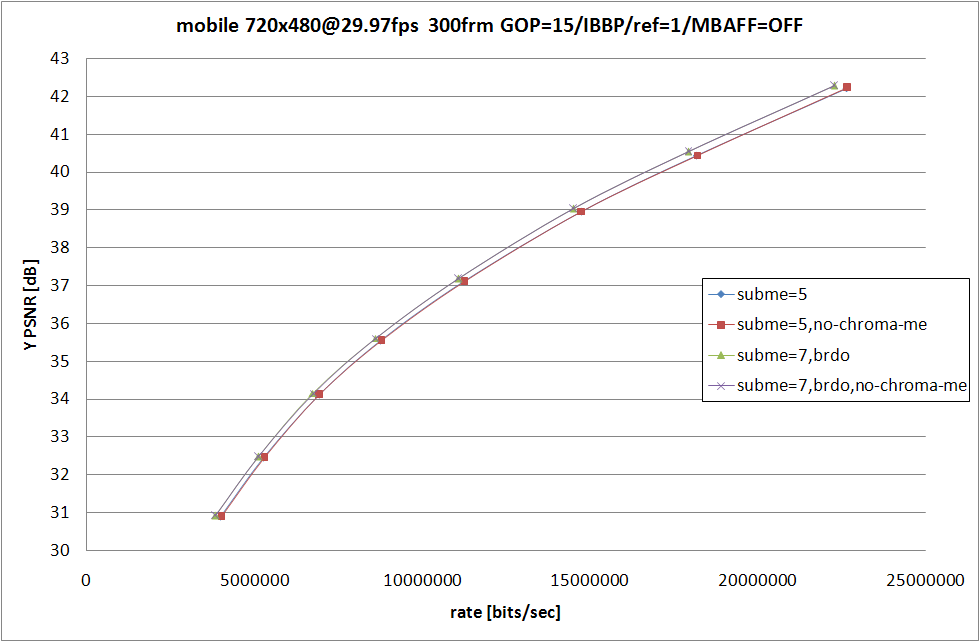
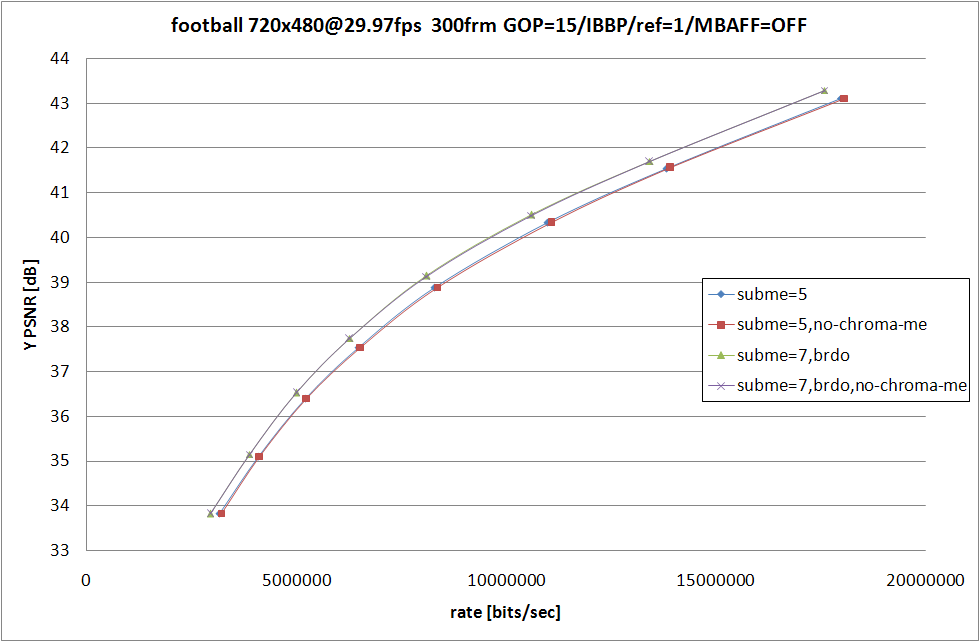
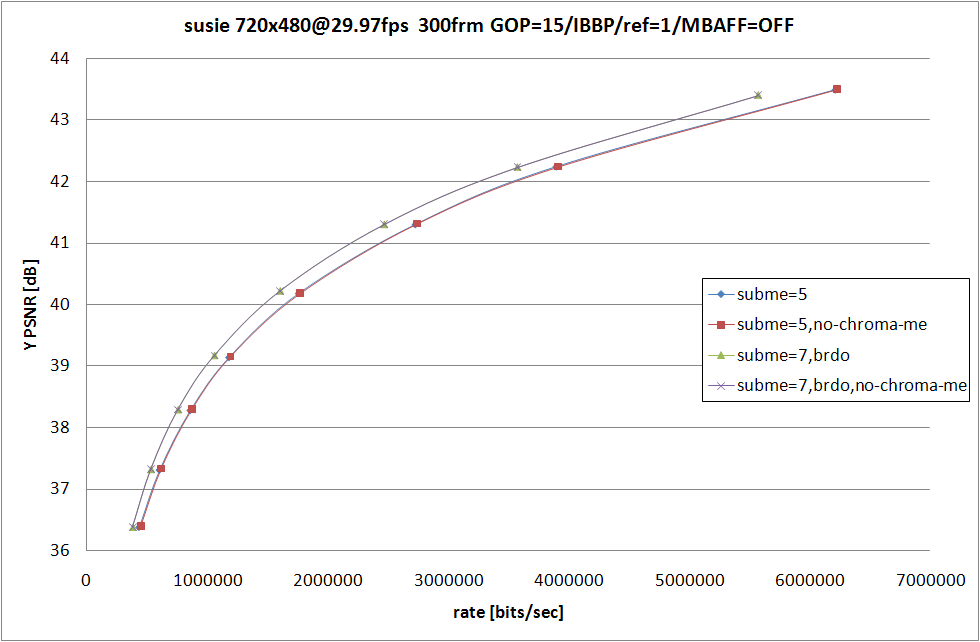
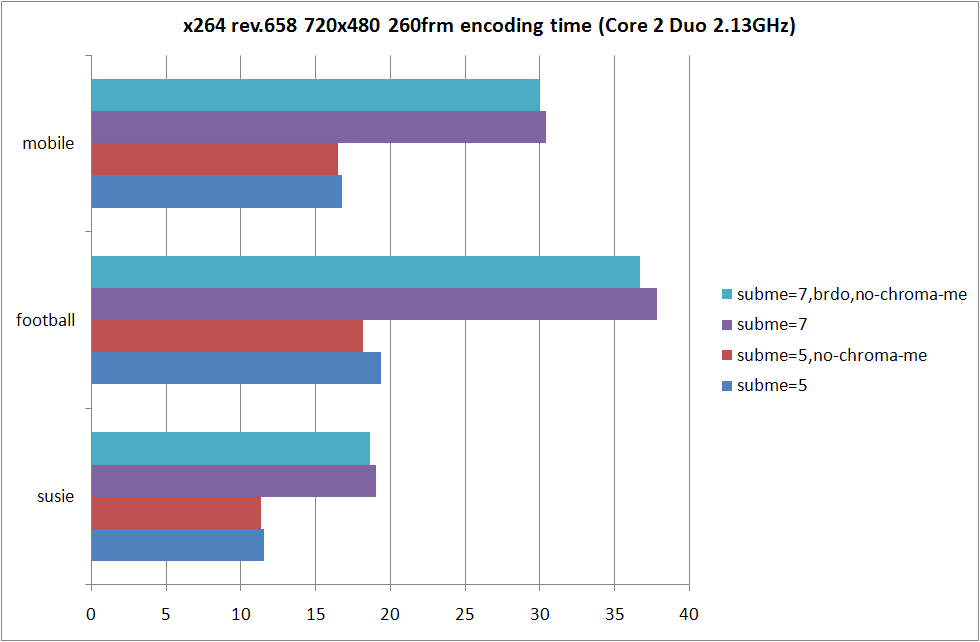
RD グラフおよび、消費時間の比較は以上の形になる。football の --subme 5 では --no-chroma-me の方が顕著に RD 性能が落ちているものの、それ以外ではグラフを見て判るほどの性能差はなし。
消費時間は --no-chroma-me を指定している側が多少なりとも高速にはなっているものの、最も差が大きい football の --subme 5 でも、比率にすれば 6.5% 程度の処理時間増加。この程度ならば許容範囲という場合が大半だと思うので、JM と厳密な比較をしたい場合以外は、わざわざ --no-chroma-me を指定する必要は無いのじゃないかと思う。
h->mb.b_chroma_me = h->param.analyse.b_chroma_me && h->sh.i_type == SLICE_TYPE_P
&& h->mb.i_subpel_refine >= 5;
なお、ソースコード上は上のような処理になっているので、P スライス、かつ subme が 5/6/7 のいずれかの場合しか chroma は動き検索に使われなくなっている。(なので、処理速度にさほど影響していないのだろう)
とりあえず ON/OFF での RD / 消費時間性能差を。恒例のグラフから。
|
|
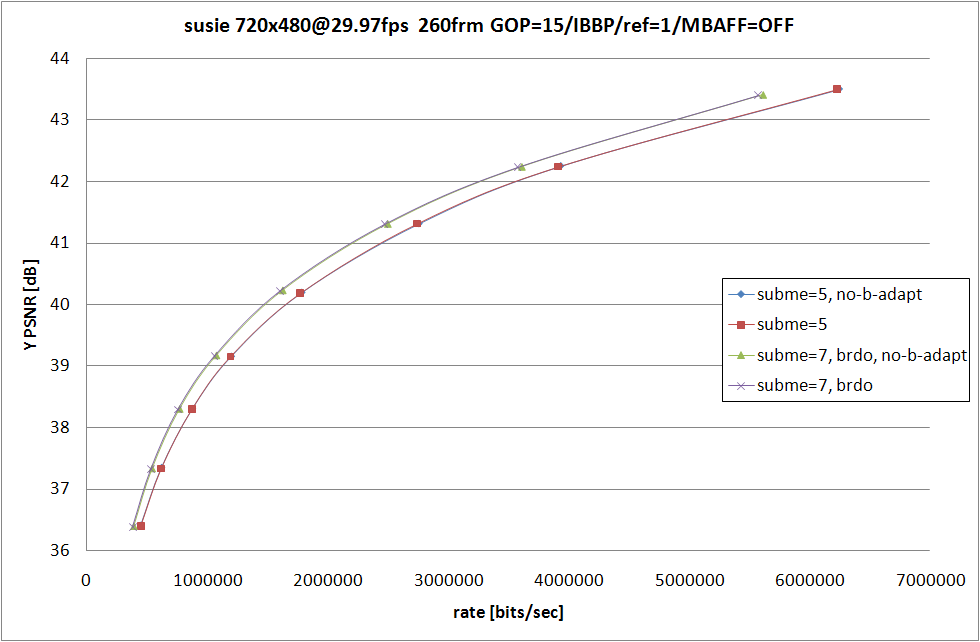
|
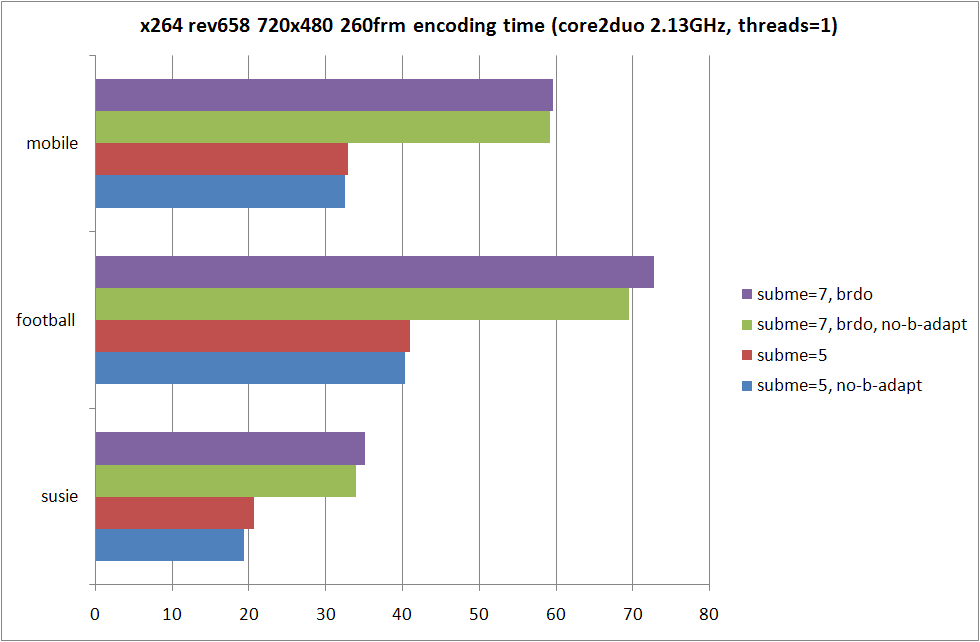
|
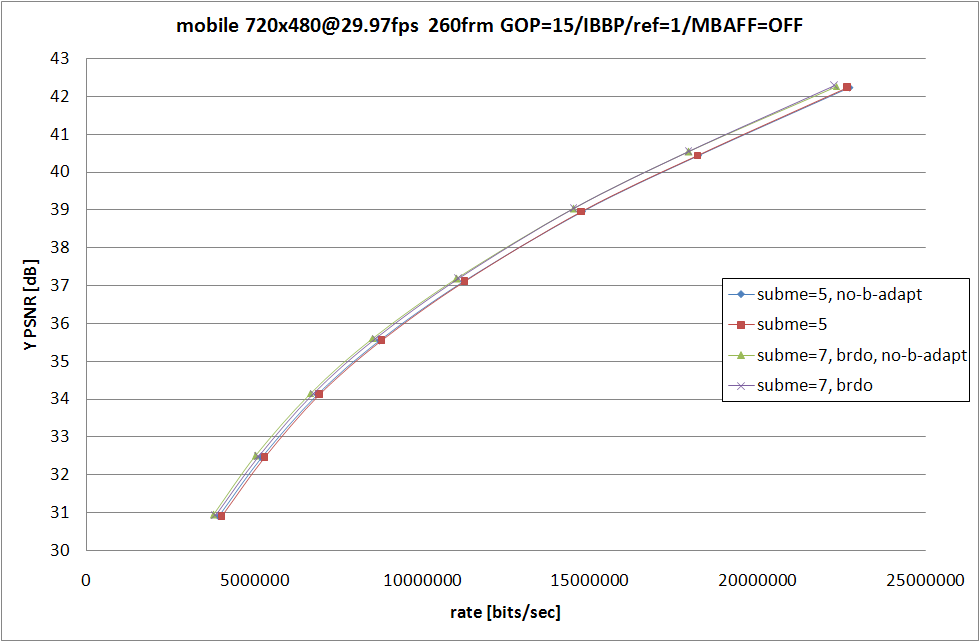
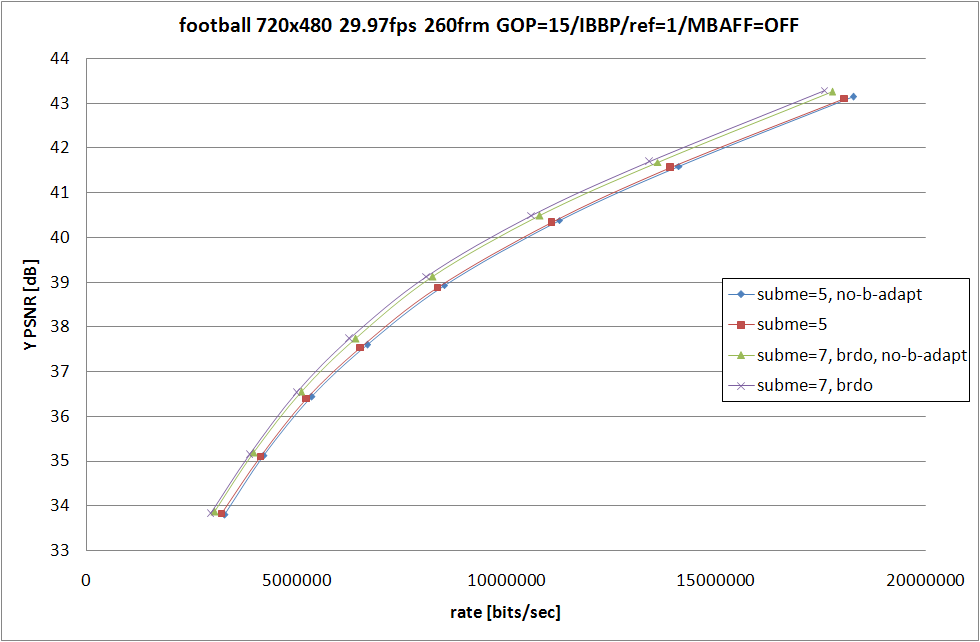
--no-b-adapt を指定した場合フレームの P/B 適応判定が無効になり --bframes 2 の場合は IBBP 形式固定でエンコード処理が行われるようになる。なお --threads 1 の場合しか --no-b-adapt は効かないので、--threads 3 を指定してた今までの約 2 倍に消費時間が増えてしまっている。
x264 [debug]: frame= 30 QP=18 NAL=3 Slice:I Poc:0 I:1350 P:0 SKIP:0 size=95286 bytes x264 [debug]: frame= 31 QP=18 NAL=2 Slice:P Poc:2 I:517 P:814 SKIP:19 size=80138 bytes x264 [debug]: frame= 32 QP=18 NAL=2 Slice:P Poc:4 I:567 P:760 SKIP:23 size=84278 bytes x264 [debug]: frame= 33 QP=18 NAL=2 Slice:P Poc:6 I:629 P:698 SKIP:23 size=85200 bytes x264 [debug]: frame= 34 QP=18 NAL=2 Slice:P Poc:8 I:586 P:738 SKIP:26 size=81777 bytes x264 [debug]: frame= 35 QP=18 NAL=2 Slice:P Poc:10 I:553 P:771 SKIP:26 size=78539 bytes x264 [debug]: frame= 36 QP=18 NAL=2 Slice:P Poc:12 I:669 P:659 SKIP:22 size=81415 bytes x264 [debug]: frame= 37 QP=18 NAL=2 Slice:P Poc:14 I:600 P:724 SKIP:26 size=81453 bytes x264 [debug]: frame= 38 QP=18 NAL=2 Slice:P Poc:16 I:739 P:588 SKIP:23 size=82496 bytes x264 [debug]: frame= 39 QP=18 NAL=2 Slice:P Poc:18 I:669 P:656 SKIP:25 size=83643 bytes x264 [debug]: frame= 40 QP=18 NAL=2 Slice:P Poc:20 I:608 P:718 SKIP:24 size=82764 bytes x264 [debug]: frame= 41 QP=18 NAL=2 Slice:P Poc:22 I:580 P:743 SKIP:27 size=83844 bytes x264 [debug]: frame= 42 QP=18 NAL=2 Slice:P Poc:24 I:769 P:554 SKIP:27 size=88750 bytes x264 [debug]: frame= 43 QP=18 NAL=2 Slice:P Poc:26 I:813 P:511 SKIP:26 size=89908 bytes x264 [debug]: frame= 44 QP=18 NAL=2 Slice:P Poc:28 I:698 P:625 SKIP:27 size=87366 bytes
--no-b-adapt を指定しない状態で動きの大きいシーンをエンコードした場合は、上記の --verbose ログのように B が使われなくなるか、IBP のように B の挿入枚数が減った形になる。
x264 [debug]: frame= 30 QP=18 NAL=3 Slice:I Poc:0 I:1350 P:0 SKIP:0 size=95286 bytes x264 [debug]: frame= 31 QP=18 NAL=2 Slice:P Poc:6 I:1243 P:87 SKIP:20 size=97152 bytes x264 [debug]: frame= 32 QP=18 NAL=0 Slice:B Poc:2 I:315 P:700 SKIP:31 size=75843 bytes x264 [debug]: frame= 33 QP=18 NAL=0 Slice:B Poc:4 I:309 P:675 SKIP:31 size=80652 bytes x264 [debug]: frame= 34 QP=18 NAL=2 Slice:P Poc:12 I:1249 P:84 SKIP:17 size=92808 bytes x264 [debug]: frame= 35 QP=18 NAL=0 Slice:B Poc:8 I:312 P:655 SKIP:30 size=78114 bytes x264 [debug]: frame= 36 QP=18 NAL=0 Slice:B Poc:10 I:331 P:680 SKIP:29 size=77398 bytes x264 [debug]: frame= 37 QP=18 NAL=2 Slice:P Poc:18 I:1281 P:45 SKIP:24 size=94694 bytes x264 [debug]: frame= 38 QP=18 NAL=0 Slice:B Poc:14 I:363 P:588 SKIP:30 size=79751 bytes x264 [debug]: frame= 39 QP=18 NAL=0 Slice:B Poc:16 I:424 P:610 SKIP:31 size=80732 bytes x264 [debug]: frame= 40 QP=18 NAL=2 Slice:P Poc:24 I:1247 P:77 SKIP:26 size=97562 bytes x264 [debug]: frame= 41 QP=18 NAL=0 Slice:B Poc:20 I:423 P:616 SKIP:30 size=81646 bytes x264 [debug]: frame= 42 QP=18 NAL=0 Slice:B Poc:22 I:480 P:552 SKIP:30 size=85278 bytes x264 [debug]: frame= 43 QP=18 NAL=2 Slice:P Poc:28 I:1065 P:263 SKIP:22 size=95092 bytes x264 [debug]: frame= 44 QP=18 NAL=0 Slice:B Poc:26 I:361 P:701 SKIP:30 size=79980 bytes
--no-b-adapt を指定した状態で同じ箇所をエンコードした場合の --verbose ログは上記の形になる。I/P の間の B スライスの数は 2 枚で固定されるけど、参照フレームとして使える I/P フレーム間の距離が開くので P スライスでのイントラ MB の数が増えてしまっているのが確認できる。
例えば frame=37 は I:1281 P:45 とほぼすべてがイントラ MB としてエンコードされている。--no-b-adapt を指定しない場合のログで同じフレームをエンコードしているのは Poc:18 の frame=39 になるのだけど、I:669 P:656 とインター MB の比率が増えてより効率よく圧縮できている。
えーと動きが大きいシーンでは参照フレーム間の距離が離れるほど予測がしづらくなるので圧縮効率が落ちるのは……特にサンプルを出さずとも納得してもらえるはず。mobile の --subme=5 では --no-b-adapt の方が RD 性能が良くなってしまっているけど、これは動きの有無を予測差分の大小で判断しているため、動きが小さいけど予測誤差が出やすい mobile では適応判定が誤爆してしまっているのだろう。(あまり真面目にコードを確認していないので間違っている可能性あり)
void x264_slicetype_decide( x264_t *h )
{
/* 途中略 */
else if( (h->param.i_bframe && h->param.b_bframe_adaptive)
|| h->param.b_pre_scenecut )
x264_slicetype_analyse( h );
/* 以下略 */
P/B 適応判定を実行する部分は上のコードになっているので、--threads が 1 よりも大きい場合は pre_scenecut が有効になって強制的にスライスタイプ適応判定が実行されてしまう。まー基本的に JM と厳密に処理を統一して比較したいときぐらいしか指定する必要のないオプションだから冷遇されてしまっているのだろう。
説明するまでもないオプションのような気もするのだけど、為念。--no-cabac は CABAC (Context Adaptive Binary Arithmetic Coding) を無効にして CAVLC (Context Adaptive Variable Length Coding) を使うように変更するオプション。
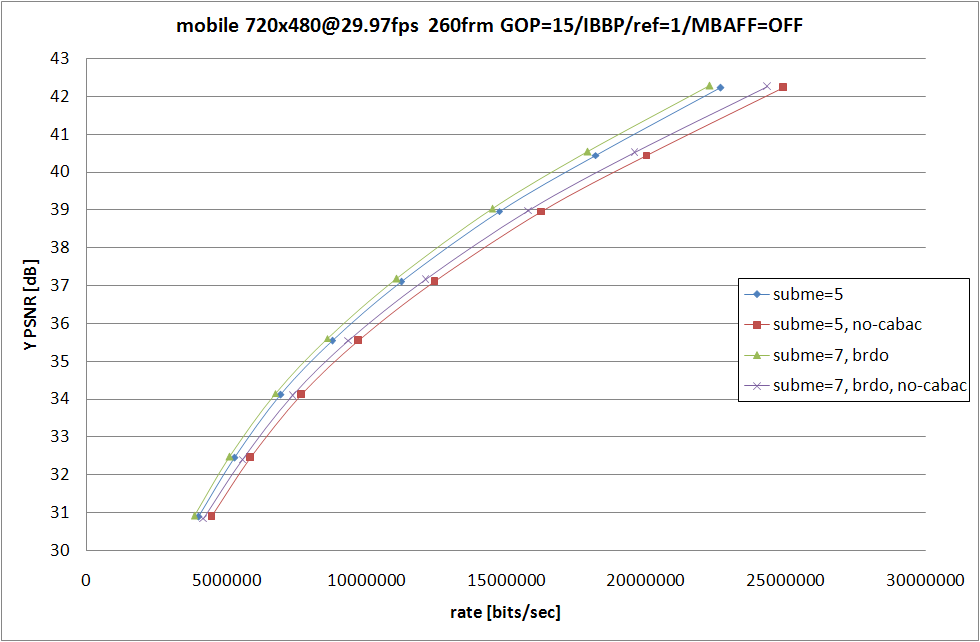
|
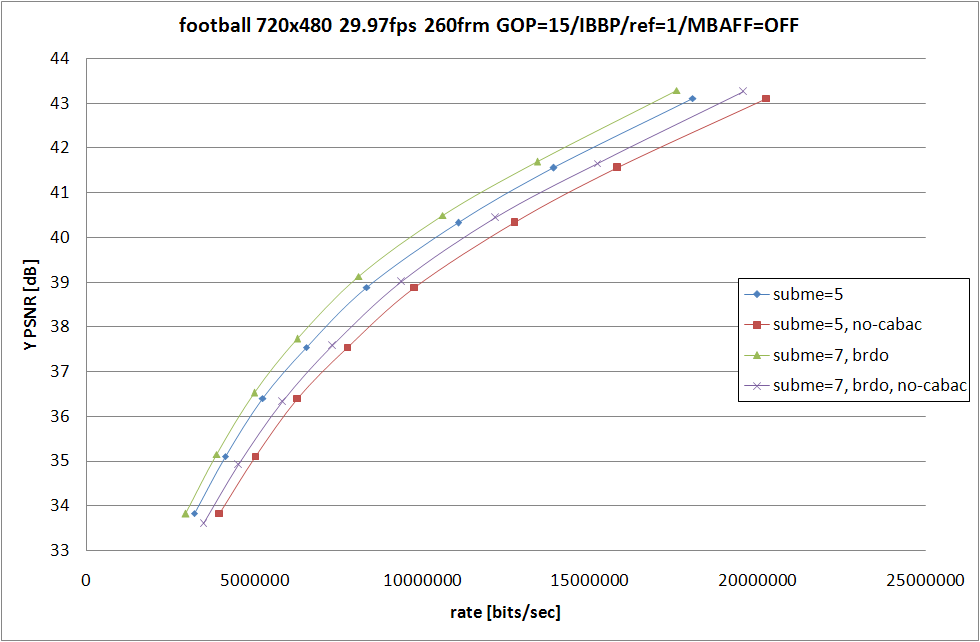
|
|
|
具体的な効果は RD グラフのとおり。圧倒的なまでの符号化効率の低下と僅かばかりの計算量削減。10〜20% 同一 QP での発生符号量が増えるという素晴らしいもの。
誰がこんなオプション使うのだろうと疑問に感じるかもしれないけど、携帯機器向けの Baseline プロファイル (ワンセグが採用してる) では、CABAC は再生負荷が高すぎるから CAVLC しか使っちゃダメという規定になってたりするので、携帯機器向けのコンテンツを作る人たちは涙を呑んで CABAC を諦めて CAVLC を使わなければいけない。再生環境で CABAC が使えないという状況以外では指定する価値は無い。
H.264/AVC では MB 間の依存関係が大きいので並列化が難しいというのが定説になっている。けれど、x264 のスレッド実装は比較的効率の良いものになっているので、どうやっているのかを紹介してみる。
以前 --ref オプションの説明の際に使った絵だけれど、P[0] フレームをエンコードする際には、P[-1], P[-2], P[-3] を参照するので、これらのエンコードが (ローカルデコードとデブロックフィルタの適用まで) 終わっていなければいけないし、B[0] フレームをエンコードするときは P[0], P[-1], P[-2], P[-3] の全フレームのエンコードが終わっていなければいけない。
で、H.264 エンコーダでの複数スレッド対応を行う場合の常套手段は 1 つのフレームを複数のスライスに分割することによって MB 間の依存関係を切り離し、各スライスに一つのスレッドを割り当ててマルチスレッド対応を行うという形 (rev.606 までの x264 の採用形式) にすることだったのだけど、これは圧縮効率の低下 (スライス境界で MB 間の情報参照ができなくなることと、CABAC のコンテキストテーブルが初期化されてしまうこととかが原因) や CPU 使用率の低下 (デブロックフィルタはスライス分割できない) を引き起こしていた。

上の図は rev.607 以降の x264 のスレッド化方針を示したもの。例えば P[0] の 1 つの MB (図の中で赤く塗りつぶしたもの) をエンコードする際に、P[-1], P[-2], P[-3] で本当にエンコードが完了していなければいけない領域というのは、MV の存在しうる範囲 (図の中では灰色で塗りつぶした領域) だけで、そこさえエンコードが完了していれば、残りは未エンコードでも処理が可能だ。
x264 で --threads 3 などとして複数スレッドを指定した場合、一つのフレームは一つのスライスのままで、フレームに対してスレッドを割り当てて、参照フレームの一定範囲 (図の中では灰色の射線で塗りつぶした領域、明示的に指定したい場合は --mvrange-thread で指定) のエンコードが完了した時点で、順次別フレームのエンコード処理を開始してしまい、並列処理を行うという形になる。
この方式の利点は、スライス分割が不要になって圧縮効率の低下をなくすことができること、面倒な同期処理を減らせてより効率よく CPU を活用できること。以上 2 点。
欠点は、シングルパスでのレートコントロールが事実上不可能になること。ただ、x264 はシングルパスでのレートコントロール機能を元々サポートしていなかったので、この欠点は無視できる。
H.264 ではブロックノイズ除去フィルタを掛けた後のフレームを、参照フレームとして以後のフレームのデコードに利用する形になっている。参照フレームとして利用される、デコードループ (デコードした画像を次の画像のでコードに利用するという繰り返し) の中にあるフィルタなので、このデブロックフィルタのことをインループフィルタと呼んだりもする。それとは逆に、WMV のように参照画像に対してはフィルタを掛けずに、表示データに対してだけフィルタを掛ける方式のことをアウトループフィルタとかオフループフィルタとか呼んだりする。
一応デブロックフィルタの ON/OFF は規格上選べるようになっているので、x264 でも ON/OFF を選択するためのオプションが用意されている。--no-deblock がそのオプションで、これを指定した場合はデブロックフィルタが無効になり、指定しなければ有効になる。

上はデブロックフィルタを ON/OFF 切り替えた場合にどうなるかを示したもの。左側がデブロックフィルタ有効で、右側がデブロックフィルタ無効のもの。口元や襟回り辺りが判りやすいはず。
--keyint 15 --scenecut 0 --bframes 2 --subme 5 --qp 26 --cqm flat --ipratio 1.0 --pbratio 1.0
サンプル作成に使用したオプションは以上。ソースは media.xiph.org から foreman (CIF) [URI] を使用。
デブロックフィルタの強度は QP に依存するのだけど QP 26 でのフィルタは上のブロックノイズを潰せるほどの強いものが適用される。--deblock オプションはデブロックフィルタの強度を調整する為のオプションで、例えば
doom9 のカスタムマトリックススレッドの人々がマトリックスと同時に --deblock の数値を変更しているのは、量子化行列の変更に伴う画質劣化の (同一 QP での) 改善を、デブロックフィルタにも反映してフィルタ強度を弱める必要があるためだ。
すぐに続きを書くつもりだったのだが、気力が尽きていたためこんなに間があいてしまった。今月中にレートコントロールのあたりまで書いてこのシリーズはおしまいにしようと思っていたのに。
本題。今回は H.264 のデブロックフィルタが、どこに、どんな時に、どんな風に掛るかについて。デブロックフィルタはその名前が示すとおりブロックノイズを潰すためのフィルタなので、ブロックノイズが発生する部分に掛けられる。ブロックノイズはブロック境界に発生するので、デブロックフィルタがかかる場所はブロック境界になる。
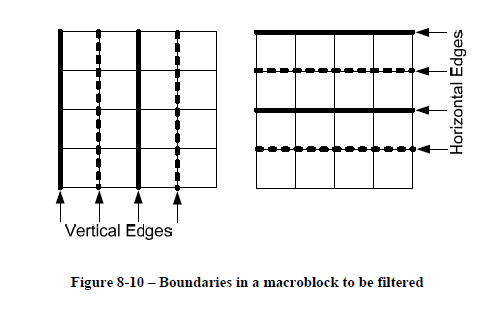
上の図は、勧告書に載っているデブロックフィルタが適用されるブロック境界を示したもの。一つの 16x16 MB は 16 個の 4x4 サブブロックに分割され、各 4x4 サブブロック境界にフィルタが掛けられる。
フィルタはブロック境界すべてに掛るわけではなく、特定の条件が成立するときだけ適用される。次のリストはその条件の一覧。(説明が煩雑になるので、今回は MBAFF を無視する)
上のリストの条件を満たせばそのブロック境界にはフィルタが適用されるのだけど、逆に言えばリストの条件を満たすことがなければフィルタは適用されない。そのフィルタが適用されない条件とは「インターMBで、同じ参照画像からの予測で、MV が似ていて、DCT 係数も持たない」ブロック境界になる。
例えば別の絵からの予測で構成されていたり、同じ絵からの予測でも別々の場所 (MV が 1 画素以上相違) から予測されている場合、そのブロック境界では違う絵が隣り合っている形になってしまうので、視覚的に目立つノイズができてしまう (のでデブロックフィルタでそれを潰す) わけなのだけど、同じ絵の同じ (MV の) 場所からの予測で構成されている場合は、ブロック境界でも連続した絵のままでいられるので、原理的にノイズは発生しない。上のフィルタが適用されない条件というのは、こういう原理的にノイズが出ない場合にフィルタ処理を行わないための、ノイズが出る場所でしかフィルタ処理を行わないためのものだ。
DCT 係数がある場合は量子化で失われたディティールがブロック境界でのノイズの元になるし、イントラ MB というのは DCT 係数がある場合のお化けのようなものなのでやはりブロック境界にノイズが出る。リストの番号が若いものほどノイズが強くでるのでデブロックフィルタの強度もより大きなものが適用されることになっている。

フィルタの強度によって何が変わるかというと、どれだけの範囲の画素に影響を与えるかが変化する。一番強いフィルタが掛る場合は、上の図で p2〜q2 までの 6 画素がフィルタで書き換えられ、最も弱いフィルタが掛る場合は p0 と q0 の 2 画素だけがフィルタで書き換えられる。(さらに弱い場合として、フィルタが無効になり一切画素を描き変えない場合がある)
実際のフィルタ処理は p0 と q0 の画素値の間の差分が閾値 alpha 未満かつ、p1 と p0 の差分と q1 と q0 の差分が共に閾値 beta 未満の場合だけ適用されて、p2 と p0 の差分も beta 未満ならば p 方向にフィルタ対象画素が広がり、q2 と q0 の差分も beta 未満ならば q 方向にフィルタ対象画素が広がる。そして二つの閾値 alpha と beta は「どのブロック境界条件が成立していたか」「ブロック境界を挟んだ平均 QP」「オプションとして指定可能なフィルタオフセット」の 3 条件で変化して、ブロック境界条件はリスト上で小さい番号のものほど大きな閾値に設定されるし、平均 QP も大きい方が (量子化誤差が大きくなり、ノイズも大きくなるので) 大きな閾値が設定される。
フィルタオフセットは他二つとは多少意味が変わって、これは平均 QP による閾値の変化を調整する為に用意されている。x264 では
この辺りの閾値がらみの処理は、量子化で発生するだろう誤差を超える画素値の差分がブロック境界にあるなら、それは原画から存在したであろう差分なので、フィルタでノイズとして除去してはいけないというロジックを反映させるために用意されている。
まー意図は判るし、必要性も理解できるから (それ以前の問題として規格になっている以上是非もないという点もあるのだけど) エンコーダ・デコーダではこれらの処理を諦めて実装する訳なのだけど、中の人の本音としては画素単位で処理を切り替える必要があるというのは、並列化とか SIMD 化とかを考える際には悪夢なので勘弁してほしいといったところ。このうえに今回は説明を省いた MBAFF で Field/Frame が混在した場合とかが出てくると絶望の扉が開きまつ。SIMD 化は不可能というわけじゃないし、やればやったなりに速度も上がるんだけど。(実際 x264 は中途半端だけど SIMD 化している)